

Linearer Text
Linearer Text mit Verweis »siehe oben«
This article describes ergonomical aspects of hypermedia systems. First, the basic concepts of hypertext, multimedia and hypermedia are defined and discussed. Then the main problems of hypertext systems, such as navigation, orientation, and search, and their possible solutions are discussed. Different methods are presented and evaluated according to their usability. The article closes with a short introduction to usability problems of different modalities.
Hypermedia gilt als umfassendes Konzept, das Hypertext mit Multimedia kombiniert. Alle drei Begriffe erfreuen sich seit einigen Jahren, vor allem im Zusammenhang mit dem Internet, großer Beliebtheit, so daß sie oftmals als reine Schlagworte ohne definitorischen Hintergrund benutzt werden. An dieser Stelle soll nicht die ausgiebige Diskussion um das Wesen der drei Konzepte nachvollzogen werden. Es ist aber sinnvoll, kurz auf die gängigen Definitionsmerkmale einzugehen, um die umgangsprachliche Austauschbarkeit[1] der Begriffe zu vermeiden.
Betrachtet man die gängigen Definitionen zu Hypertext, so
kristallisieren sich zu dieser Frage zwei Punkte heraus: Erstens wird Hypertext
unter verschiedenen Aspekten definiert, sei es als Autorenwerkzeug zur
Erstellung und Kommentierung von
Texten,[2]
als Technik der Informationsspeicherung und
-verwaltung[3]
oder als Methode der
Informationspräsentation.[4]
Auf Anwenderseite wird vor allem der Aspekt der Informationspräsentation
interessieren. Zweitens findet sich üblicherweise der Begriff
›Nicht-Linearität‹ in den Definitionen wieder. Er bezieht sich
auf einen prinzipiellen Unterschied zwischen Hypertexten und traditionellen
Texten. So werden traditionelle Texte beispielsweise in Buchform publiziert und
können von der ersten bis zur letzen Seite durchgelesen werden. Solche
Texte werden als ›linear‹ bezeichnet. Die Aufgabe des Autors liegt
hier neben der reinen Niederschrift der Information auch darin, diese in einer
sinnvollen Reihenfolge vorzustellen. Der Anwender eines linearen Textes
muß diesen nur noch von Anfang bis Ende durchlesen und kann sich dabei
gänzlich auf die Informationsaufnahme konzentrieren.
Hypertexte hingegen bestehen aus einzelnen Textsegmenten, die durch Verweise (›links‹) miteinander verbunden sind. Eine vom Autor vorgegebene Reihenfolge des Lesens besteht zunächst nicht. Der Anwender kann im Informationsangebot selbständig eigene Lesewege einschlagen und sich jeweils auf die ihm interessant erscheinende Information konzentrieren.
Diese Unterscheidung zwischen linearem Text und Hypertext ist idealtypisch. Für den Hypertext typische Elemente, wie Linkstrukturen und Segmentierungen, sind auch dem traditionellen Text nicht vollkommen unbekannt. So wird linearer Text für gewöhnlich in Kapitel beziehungsweise Abschnitte segmentiert, und Verlinkungen werden beispielsweise durch Anmerkungen, Fußnoten oder Querverweise ausgedrückt. Lexika und Wörterbücher etwa sind hochgradig verlinkte Textsorten mit relativ kleinen Textsegmenten und daher sehr dankbar für die Übernahme in ein Hypertextsystem. Andere Textsorten, wie beispielsweise Romane, eignen sich hingegen kaum für die Übernahme in ein Hypertextsystem. Sie lassen sich nur bedingt in sinnvolle Segmente unterteilen und benötigen aufgrund ihres sukzessiven Aufbaus keine Verlinkung.[5]
|
|
|
|
Abb. 1a: Linearer Text |
Abb. 1b: Linearer Text mit Verweis »siehe oben« |
Die Faszination für Hypertext erklärt sich aus den zahlreichen Möglichkeiten, die sich durch das Konzept ergeben[6]: So wird zunächst die Arbeit mit Querverweisen zwischen Textstellen stark erleichtert. Beim Editieren eines Hypertextes können neue Querverweise leicht erstellt werden, so daß Anwender vergleichsweise einfach eigene Textnetzwerke aufbauen oder vorhandene Texte anderer Autoren mit Kommentaren versehen können. Durch die Segmentierung des Textes können mehrere Autoren gleichzeitig arbeiten, ohne sich gegenseitig zu stören. Das Verfolgen der Querverweise durch den Leser ist in elektronischer Form im Gegensatz zu traditionellen Büchern nicht mehr mit Blättern verbunden, sondern durch einen einfachem Mausklick schnell und ohne Aufwand durchführbar.
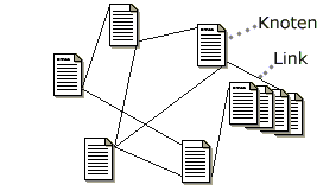
Dieser intensive Einsatz von Querverweisen bietet eine alternative Suchstrategie zu traditionellen Indizes. Beim sogenannten ›Browsen‹ (englisch: ›abgrasen‹) wird der vom Hypertext beschriebene Informationsraum assoziativ durchschritten. Die Suche gestaltet sich hierbei deutlich explorativer als es mit einem einfachen Index möglich wäre. Durch ein hohes Maß an Interaktivität können dem Anwender neue Wege der Informationssuche erschlossen werden.
Durch die Flexibilität der Querverweise wird auch ein hohes Maß an Flexibilität und Individualisierbarkeit in der Textstruktur erreicht. So kann eine Sammlung von Textsegmenten, die technisch gesehen an sich zunächst vollkommen unstrukturiert sind, durch verschiedene Linkstrukturen verbunden werden. Dann können beispielsweise unterschiedliche Lesergruppen anders an den gleichen Text herangeführt werden oder unterschiedlich tief in die vom Hypertext beschriebene Thematik einsteigen. Auch kann auf gleiche Textsegmente von verschiedenen Stellen aus referiert werden, so daß eine Idee nur einmal formuliert werden muß, aber dennoch an verschiedenen Stellen eingeführt und erläutert werden kann. Trotz dieser Flexibilität besteht dennoch ein hohes Maß an Konsistenz, da die Querverweise fest an den Text gekoppelt sind und automatisch mitgeführt werden, wenn ein Textsegment seine Position innerhalb der Hypertextstruktur wechselt.
Die Konzeption von Hypertexten erlaubt es ferner, neben der Anzeige einzelner Seiten auch globale Ansichten des Textes zu betrachten. Solche Ansichten können automatisch generiert werden und bieten einen Überblick über die Struktur eines Hypertextes oder eines seiner Teilsysteme.
Diesen Vorteilen von Hypertext sind gleichzeitig zwei gravierende Nachteile implizit: Da ist zunächst die kognitive Mehrbelastung (Cognitive Overhead), also die notwendige Anstrengung, um die Querverweise und die Struktur eines Hypertextes zu erkennen und zu nutzen. So muß der Leser bei jedem Textsegment entscheiden, welchen Querverweis er von hier aus weiterverfolgen will. Zusätzlich müssen mitunter mehrere verschiedene Aufgaben gleichzeitig bearbeitet werden, wie das inhaltliche und strukturelle Erfassen des Textes. Hierbei kommt hinzu, daß aufgrund der Flexibilität verschiedene Wege durch den Text eingeschlagen werden können und der Leser mehrere solcher Wege ausprobieren kann. Möchte er verschiedene Querverweise ausprobieren, so muß er sich die Abzweigung merken, zu der er zurückkehren will. Dies führt schnell zum zweiten Problem, der Orientierungslosigkeit.
Während lineare Texte einen Verlust der Orientierung nur schwer zulassen, führen die Verzweigungsmöglichkeiten des Hypertextes relativ schnell zu Verwirrung, da keinerlei räumliche Hinweise auf die momentane Position im Gesamtsystem gegeben wird. Der Leser befindet sich plötzlich auf einer Textseite ohne zu wissen, wie er dort hingekommen ist, wie er von dort weitergehen soll und was er überhaupt auf dieser Seite will. Zwei Phänomene treten dabei zu Tage:[7] Zum einen das Phänomen der Ablenkung. Beim Browsen werden solange Querverweise verfolgt, die gerade interessant erscheinen, bis die aufgeschlagene Seite nichts mehr mit dem ursprünglichen Informationsbedürfnis zu tun hat. Zum anderen das sogenannte ›Kunstmuseum-Phänomen‹. Ähnlich einem längeren Aufenthalt in einem Kunstmuseum kann auch längeres Browsen dazu führen, daß die einzelnen Eigenschaften der betrachteten Gegenstände beziehungsweise Seiten nicht mehr abstrahiert werden und somit keine grundlegende Idee mehr erkennbar ist.
Die Liste der Vorteile und Probleme von Hypertextsystemen wird durch die Integration von Multimedia noch erweitert. Multimedia bedeutet Verwendung verschiedener Medien, wie Video, Audio, Text et cetera.[8] Die Effekte von Multimedia sind am weitesten in der Lernforschung beschrieben. Hier wird vor allem der positive Effekt verschiedener Modalitäten auf die Lernleistung hervorgehoben. Besonders im Bereich ›Illustration‹ scheint hier die Forschung am weitesten fortgeschritten. Illustrationen können unter bestimmten Bedingungen zu einer signifikant erhöhten Lernleistung führen. Problematisch ist hier jedoch, daß dies nicht für Illustrationen an sich gilt, sondern im negativen Fall Illustrationen sogar einen gegenteiligen Effekt haben können. Richtlinien für die Gestaltung sind hier mitunter sehr vage formuliert. Für andere Modalitäten wie Tonaufnahmen, Animationen oder Videos sieht die Lage noch schwieriger aus.
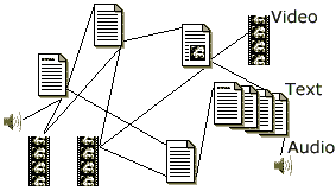
Reine Hypertext- oder Multimediaanwendungen, wie sie hier strikt voneinander getrennt definiert wurden, sind selten. In der Regel werden beide Konzepte zu Hypermedia kombiniert. Die Probleme bezüglich dieser Kombination wirken, wie auch die Vorteile, additiv: Für den Anwender gelten nun sowohl die Schwierigkeiten der Orientierung als auch die des Umgangs mit den verschiedenen Medien. Im folgenden soll ein Überblick über bestehende Konzepte zur Lösung oder wenigsten Milderung dieser Probleme gegeben werden. Der Überblick orientiert sich dabei am Begriff ›Hypermedia‹ selbst und geht zunächst auf die Probleme des ›Hyper-‹, also der Orientierung, und später auf die Probleme der ›-media‹, also des Einsatzes verschiedener Medien, ein.
Probleme bei der Orientierung treten in Hypermediasystemen dann auf, wenn man auf der Suche nach einer bestimmten Information ist. Sei es, daß man eine bereits besuchte Seite wiederfinden möchte, sei es, daß man ein bestimmtes Informationsbedürfnis hat, auf welches man sich eine Antwort erhofft. Beim unbestimmten Browsen, wie es mit dem World Wide Web (WWW), dem größten existierenden Hypermediasystem, aufkam, wird ein Verlust an Orientierung weniger als Ärgernis wahrgenommen als beim gezielten Navigieren.
Die ursprüngliche Intention bei der Konzeption von Hypertext Mitte der 1940er Jahre lag jedoch gerade in der Unterstützung bei der Auffindung von Information. Ziel war es, zu Index-Systemen eine Alternative zu finden, die über Assoziationen neue Information zugänglich macht. Das Auffinden relevanter Information wird mit wachsendem Umfang des Systems immer weiter erschwert.
Verschiedene Methoden und Strategien können den Anwender von Hypermediasystemen bei der Suche nach relevanter Information unterstützen. Prinzipiell kann man diese Strategien in zwei grobe Bereiche unterteilen. Der erste Bereich macht sich die Verlinkung von Hypertexten zu Nutze und unterstützt den Anwender bei der Navigation durch den Informationsraum. Die zweite Strategie zielt direkt auf die Knotenpunkte des Hypermediasystems und ermöglicht dem Anwender die direkte Suche nach bestimmten Inhalten.
Die einzelnen Knoten (zum Beispiel Textsegmente) eines Hypermediasystems werden durch sogenannte ›Links‹ (Querverweise) miteinander verknüpft. Diese Verlinkung und ihre Präsentation ist von entscheidender Bedeutung für die mögliche Qualität der Navigation. Führen die Links zu uninformativen Knoten oder gar ins Leere, leidet die Navigation naturgemäß darunter. Beide Defizite sind eng mit zwei verschiedenen Linktypen verbunden: den statischen und den dynamischen Links. Für gewöhnlich werden in Hypertextsystemen statische Links verwendet, in HTML (Hypertext Markup Language) beispielsweise durch die Auszeichnung (›tag‹) <HREF>. Im WWW führt diese harte Verknüpfung immer wieder zu dem berüchtigten Fehler »HTTP 404 – Datei nicht gefunden«. Gerade bei umfangreichen Systemen, die ständigen Veränderungen unterworfen sind, läßt sich ein solcher Fehler ohne spezielle Werkzeuge nicht vermeiden.
Dynamische Links werden während der Laufzeit generiert und können somit nicht ins Leere führen, da sie naturgemäß immer auf dem aktuellsten Stand sind. Solche Links verweisen in der Regel auf Knoten, die zum gerade betrachteten ähnlich sind. Die Ähnlichkeit zwischen zwei Knoten kann auf der Basis ihres Inhalts auf verschiedene Arten ermittelt werden, sei es durch mathematische Funktionen[9] oder neuronale Netze.[10] Diese Bewertung von Ähnlichkeit läßt allerdings das eigentliche Informationsbedürfnis des Anwenders außen vor. So können zwei Seiten objektiv zwar einander durchaus ähnlich sein, nur in bezug auf die Fragestellung, die den Leser gerade beschäftigt, inhaltlich vollkommen divergieren. Hier führt ein Link von einer informativen zu einer uninformativen Seite.
In der Praxis werden dynamische Links selten über diese Anwendung hinaus eingesetzt. Von der Idee her sind sie jedoch den statischen weit überlegen. Können sie doch zwei entgegengesetzte Ziele miteinander zumindest theoretisch in Einklang bringen: Zum einen verfolgen sie das Ziel, dem Anwender zu einem Knoten genau den einen Link zu geben, der ihn zu dem für ihn relevanten nächsten Knoten führt, und zum anderen sollen sie möglichst für jedes mögliche Informationsbedürfnis den entsprechenden Link präsentieren. Auf der Basis von Faktoren wie Benutzermodel,[11] Navigationsweg und Kontext könnte der entsprechende Link automatisch generiert werden.
Eine beliebte Methode, die Navigation zu unterstützen, ist die Einführung einer hierarchischen Struktur[12]: Verschiedene Knoten werden unter einem Knoten zusammengefaßt. Solche Hierarchien sind dem Anwender bereits aus dem Dateimanager seines Betriebssystems sowie den Menüs der meisten Programme bekannt. Die Probleme der Hierarchien sind ebenfalls aus diesen Anwendungsgebieten bereits bekannt. Eine hierarchische Gliederung ist kein Selbstzweck, der automatisch zu leichterer Bedienbarkeit führt. Wichtig ist zunächst, daß die Hierarchie dem Anwender auch präsentiert wird. Sonst kann er sich nur schwer ein mentales Model zur tatsächlichen Struktur aufbauen. Oftmals wird jedoch auf eine solche Präsentation aus Platzgründen zugunsten des Inhalts verzichtet.
Um dem Anwender ein Verständnis der tatsächlich genutzten Hierarchie zu ermöglichen, ist es notwendig, ihre Struktur darzustellen. Prinzipiell eignen sich dafür zwei verschiedene Versionen. Bei Hierarchien, die auf Breite angelegt sind, haben sich im Internet Navigationsspalten als vorteilhaft erwiesen. Hier wird an einer Bildschirmseite Platz für die Darstellung der Hierarchie reserviert, wobei die einzelnen Punkte einer Ebene untereinander aufgeführt und die Punkte einer Unterebene leicht eingerückt werden. Der Nachteil dieser Methode liegt im relativ großen Platzverbrauch. So steht für den Inhalt der Seite deutlich weniger Platz, oftmals 20-30%, zur Verfügung als dies ohne eine Navigationsspalte der Fall wäre.
Eine weniger platzintensive Darstellung ist die oftmals in Anlehnung an das Märchen von Hänsel und Gretel als ›Brotkrumen-Navigation‹ bezeichnete Nagivationsleiste. Sie legt die einzelnen Punkte der Navigation in der Vertikalen aus und eignet sich daher vor allem für die Darstellung von tiefen Hierarchien.[13] Bei dieser Variante wird der Pfad zur aktuellen Seite aufgezeigt. Parallele Seiten auf einer Ebene erscheinen dabei nicht.
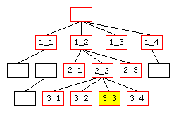
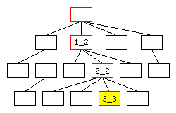

Abbildung 4 zeigt den prinzipiellen inhaltlichen Unterschied der beiden Darstellungsarten. Der aktuell angezeigte Knoten ist in der graphischen Darstellung gelb markiert. Die Konoten, die zusätzliche in der Navigationsdarstellung angezeigt werden, sind rot umrahmt. Die Navigationsspalte zeigt rot markiert sämtliche vorhandenen Knoten auf den Ebenen der Knoten, die auf dem Weg vom Ausgangsknoten zum gelb markierten aktuellen Knoten geöffnet wurden. Diese erscheinen in der Navigationsspalte untereinander, wobei die unterschiedlichen Ebenen unterschiedlich weit eingerückt sind. Bei dieser Vorgehensweise durchbricht die Anzahl der dargestellten Knoten schnell die auf dem Bildschirm darstellbare Größe. In der Regel wird daher die Anzahl der angezeigten Knoten beispielsweise auf die Knoten der aktuellen Ebene sowie den Knoten zwischen dem Ursprungsknoten und dem aktuellen Knoten reduziert. In diesem Fall würden in der Navigationsspalte die zusätzlichen Knoten der zweiten Ebene (2_1, 2_3) nicht angezeigt werden.
Die Navigationsleiste hingegen stellt von vornherein nur relativ wenige Knoten dar, nämlich die Knoten zwischen dem aktuellen und dem Ausgangsknoten. Parallele Knoten der verschiedenen Ebenen werden nicht angezeigt.
Der Aufbau einer Hierarchie erfolgt oftmals nach rein inhaltlichen Kriterien, wobei Tiefe und Breite der Hierarchie allein aus inhaltlichen Erwägungen bestimmt werden. Dies scheint zunächst ein einleuchtendes Vorgehen zu sein, jedoch ist es erstaunlicherweise so, daß inhaltliche Überlegungen gegenüber rein formalen in bezug zur Anwenderfreundlichkeit sekundär sind. So kann ein Hypertext in inhaltlich unterschiedlichen Hierarchien gegliedert werden, ohne daß sich dies auf seine Lesbarkeit unbedingt auswirken muß. Tatsächlich gibt es auch in den seltensten Fällen eine Gliederung, die sich von Natur aus ohne Alternative anbietet. Die formale Struktur kann jedoch stark unterschiedlich nutzbar sein. So stellten sich flache und damit breite Hierarchien gegenüber tiefen in Anwendertests eindeutig als vorteilhaft heraus.[14] Besonders günstig scheint dabei zu sein, wenn die oberste Ebene aus wenigen signifikanten Knoten besteht und von einer Ebene mit deutlich mehr Knoten gefolgt wird.
Eine wichtige Funktion eines Hypertextsystems ist die Möglichkeit, zu bereits besuchten Seiten zurückzukehren: das ›Backtracking‹. Diese Funktion kommt dann zum Einsatz, wenn der Anwender zu einer in der laufenden Sitzung bereits besuchten Seite zurückkehren will. Gehen beispielsweise von einer Seite verschiedene Verzweigungen ab, so wird der Anwender diese Seite immer wieder ansteuern wollen, wenn er die einzelnen Verzweigungen untersuchen will. Dabei stellt sich die Frage, wie bereits mehrfach besuchte Seiten verwendet werden sollen. Hier gibt es prinzipiell fünf unterschiedliche Modelle:
| Backtrack-Modell | Originalsequenz | Backtrack-Sequenz |
| chronologisch | A-B-C-D-C-E | E-C-D-C-B-A |
| zuletzt wiederholt besucht | E-C-D-B-A | |
| zuerst wiederholt besucht | E-D-C-B-A | |
| ohne Umwege mit Startknoten | E-C-B-A | |
| ohne Umwege/Startknoten | E-B-A |
Im chronologischen Modell werden alle Seiten exakt entsprechend der Reihenfolge, in der sie besucht wurden, auch beim Zurückgehen besucht. Eine Seite, die zweimal aufgemacht wurde, taucht also beim konsequenten Zurückgehen auch wieder zweimal auf. Dieses Modell ist am einfachsten zu implementieren und zu erkennen. Jedoch wird es schnell unübersichtlich, sobald der Anwender einen Knoten mehrfach angesehen hat.
Es ist günstiger, die Mehrfachnennung solcher Knoten zu vermeiden, wobei sich verschiedene Strategien unterscheiden lassen. Zum einen lassen sich einfach die wiederholt besuchten Knoten entfernen. Dabei stellt sich die Frage, ob das erste oder letzte Vorkommen eines solchen Knotens bestehen bleiben soll. Zum anderen können aber auch offensichtliche Schleifen und Umwege in der Navigation ausgeblendet werden, wobei sich hier wiederum die Frage stellt, ob der Ausgangsknoten eines Umweges ebenfalls ausgeblendet wird. Es spricht viel dafür, wiederholt aufgesuchte Knoten auszublenden. Welches der vier alternativen Modelle benutzt werdeb soll, ist jedoch fraglich, da alle nicht intuitiv erschließbar sind und in der Anwendung Probleme bereiten. Zu welcher Seite der Anwender schließlich zurückkehren will, kann keines der Modelle wissen.
In Internet-Browsern wird für Backtracking ein »Zurück«-Button zur Verfügung gestellt.[16] Dieser ermöglicht es, Server- und Site-unabhängig zu vorher angesteuerten Seiten zurück zu finden. Dieser Button erfüllt zwei für Hypertextsysteme wichtige Funktionen: Zum einen ist er stets vorhanden. Der Anwender hat also jederzeit die Möglichkeit, aus einer Sackgasse wieder herauszunavigieren und an den Punkt zurückzukehren, von wo aus er in die falsche Richtung abzweigte. Zum anderen läßt sich mit diesem Button die gesamte Navigation bis hin zum Ausgangspunkt zurückverfolgen. Der »Zurück«-Button ist der Ariadne-Faden, den der Anwender bei der Navigation durch Hypertexte in der Hand hält, und als solcher muß er implementiert sein: stets in der Hand und zurückführend bis hin zum Einstieg.[17]
Eine dem »Zurück«-Button ähnliche Methode, auf bereits besuchte Knoten zurückzukehren, ist die »History«-Liste. Diese gibt in chronologischer Reihenfolge die bereits besuchten Knoten wieder. Im Unterschied zum Backtracking sind hier jedoch direkte Sprünge über mehrere Seiten hinweg möglich. Ähnlich wie beim Backtracking können auch hier mehrfach besuchte Links eliminiert werden. Eine »History«-Liste kann entweder in Form textueller Links, ikonographischer Abbildungen der besuchten Knoten oder als Kombination aus beidem bestehen. Je nach Art des Knotens eignet sich eine andere Form der Darstellung besser. Textintensive Knoten werden besser durch textuelle Links repräsentiert, während andererseits bei stark graphischen Knoten eine bildliche Darstellung besser geeignet ist, da sie den Wiedererkennungswert erhöht.
Neben der automatischen Speicherung sollten Knoten, die von besonderem Interesse sind, durch »Lesezeichen« (›bookmarks‹) markiert werden können. Solche »Lesezeichen« sind besonders bei umfangreichen Systemen vorteilhaft, da der Anwender jederzeit an einer ihm vertrauten Stelle in den Hypertext einsteigen kann, ohne diese Stelle erst mühsam suchen zu müssen. Hersteller von Internet-Browsern haben diese Funktion weitgehend realisiert und mitunter sogar um eine ausgefeilte Verwaltung bereichert.
Hypertexte erhalten ihre Struktur durch die Einrichtung von Querverweisen durch den Autor. Es liegt in der Natur von Hypertexten, nicht die einfache lineare Struktur traditioneller Texte widerzuspiegeln, sondern komplexere aufzubauen. Ein Grundproblem dieser Vorgehensweise liegt darin, daß die Struktur, die dem Hypertext vom Autor zugewiesen wurde, dem Leser wiederum nicht offensichtlich ist. Er muß sie sich erst erschließen. Dabei kann es leicht vorkommen, daß die vom Leser erschlossene Struktur weit von der vom Autor intendierten entfernt ist. Entsprechend schwer wird er erfolgreich in ihr navigieren können. Es ist daher von Vorteil, dem Leser einen Überblick über einige zentrale Knoten des Hypertextes zu geben. Solche zentralen Knoten werden ›Landmarks‹ genannt und können entweder vom Autor einer Seite nach inhaltlichen Kriterien definiert oder vom System automatisch generiert werden. Die automatische Generierung von Landmarks geht in der Regel davon aus, daß zentrale Knoten entweder stark verknüpft sind oder direkt mit stark verknüpften zusammenhängen, eine hohe Besuchsfrequenz haben und in einer hierarchischen Struktur relativ weit an der Oberfläche sitzen.[18]
In hierarchischen Strukturen sind Landmarks in der Regel gut zu verwenden. Folgt man beispielsweise beim Design einer Web-Seite den Regeln des Yale Styleguides, so befindet sich am linken Rand der Seiten eine Navigationsspalte. Diese Navigationsspalte ähnelt den von Dateiverwaltungssystemen wie dem MS Explorer bekannten Struktogrammen. Hier stehen am Einstieg der Seite die verschiedenen Landmarks, unter denen weitere Punkte aufgeklappt werden können. Die Landmarks sind, im Gegensatz zu nicht aktuellen Unterpunkten, stets zu sehen und können von jeder Seite aus angeklickt werden. Diese Vorgehensweise hat mehrere Vorteile: Zum ersten hat der Anwender stets einen Überblick darüber, in welchem Bereich er sich befindet (Downloads, Kontakt, Datenangebote, et cetera). Dies ist vor allem dann sinnvoll, wenn er über eine Suchmaschine direkt auf die Seite verwiesen wurde und nicht den Einstieg über die Homepage gewählt hat. Zweitens wird eine schnelle Navigation über mehrere Bereiche möglich, ohne zuerst auf die oberste Hierarchieebene zurückkehren zu müssen.
Gerade bei der ersten Konfrontation mit einem neuen Hypertext ist es für den Anwender am wichtigsten, sich einen Überblick über die präsentierten Elemente zu verschaffen. Landmarks sind dafür zwar durchaus nützlich, jedoch helfen sie eher, schon Gesehenes wiederzufinden, beziehungsweise gezielt nach bestimmter Information zu suchen. Für einen wirklichen Überblick eignet sich besser eine sogenannte ›Guided Tour‹ (Führung). Gleich einer Museums- oder Stadtführung weist sie den Anwender auch auf nicht gleich offensichtliche Inhalte hin, erklärt zunächst Unverständliches und verschafft einen allgemeinen Überblick über das Angebot, der es ermöglicht, sich später gezielt mit einzelnen Teilbereichen auseinanderzusetzen.
Angebote wie Führungen richten sich also vor allem an neue Anwender, die sich im präsentierten Material noch nicht gut auskennen. Fortgeschrittene Anwender lassen sich weniger gern durch Führungen bevormunden, sondern wollen sich selbst einen Überblick verschaffen. Sie verzichten daher in der Regel auf Führungen zugunsten anderer Strategien wie zum Beispiel der Überblickssuche in Karten (›map‹). Diese sind vor allem für Anwender interessant, die sich in Grundzügen sowohl mit dem System als auch mit der präsentierten Materie auskennen. Von der Funktionalität ähneln solche Karten üblichen Landkarten: sie zeigen, wo im Hypertext der Anwender sich gerade befindet, wohin er gehen kann und geben ihm einen Überblick über die Umgebung. Dabei können Karten Ausschnitte oder den gesamten Hypertext zeigen und interaktiv eine Ausschnittsvergrößerung anbieten.
Der Begriff ›Karte‹ ist an dieser Stelle etwas irreführend, da es sich bei Karten nicht unbedingt auch um graphische Repräsentationen handeln muß, sondern durchaus auch textuelle Karten gängig sind. Textuelle Karten können als einfache Auflistung der Inhalte auftreten. Dies ist zwar die wohl am leichtesten zu realisierende Variante, jedoch wird dem Anwender dabei kaum ein geeignetes Werkzeug in die Hand gegeben, um einen Überblick über die Struktur des Inhalts zu bekommen. Geeigneter ist hier die Verwendung räumlicher Layouts, welche die Inhalte optisch gliedern. So fällt es dem Anwender leichter, sich ein mentales Modell der inhaltlichen Struktur des Angebots zu verschaffen. Graphisch aufbereitete Karten sind allerdings schwieriger zu generieren als reine Auflistungen von Inhalten. Sie müssen nicht nur die Inhalte und eine geeignete räumliche Verteilung berücksichtigen, sondern stoßen immer wieder an die Grenzen der räumlichen Darstellbarkeit: Der Übersichtscharakter wird zerstört, indem die Darstellung die Grenzen des Bildschirms sprengt.
Hier tritt ein generelles Problem graphischer Darstellung von Daten auf: Graphiken sind in der Lage, deutlich mehr Daten darzustellen als Texte. Wollte man beispielsweise den Inhalt einer Landkarte textuell beschreiben, so würde die resultierende Beschreibung nicht nur ein Vielfaches des Raumes einnehmen, den eine Graphik benötigt, sondern sie würde auch vollkommen unverständlich werden. Eine Graphik ist in der Lage, komplexe Daten übersichtlich und verständlich zu transportieren. Bei der Darstellung am Bildschirm treten jedoch zwei sich ausschließende Ziele auf: Zum einen möchte der Anwender möglichst einen Überblick über das Dargestellte erhalten. Es sollte also möglichst der gesamte Inhaltsraum in der Graphik präsentiert sein. Zum anderen soll aber auch auf Detailebenen gearbeitet werden können. Die Darstellung muß also eine genügend hohe Auflösung haben, um auch Details des Inhaltsraumes erkennbar darstellen zu können. Will man beide Anforderungen in einer Karte umsetzen, so steht man im Extremfall vor der Aufgabe, in einer Karte den Detailgrad eines Stadtplans mit der Übersichtlichkeit einer Weltkarte zu verbinden.
Hier gibt es verschiedene mehr oder weniger elegante Lösungen, wobei keine dieser Lösungen als ideal angesehen werden, sondern selbst wieder zu Schwierigkeiten in der Handhabung führt. So können beispielsweise analog zu üblichen Hierarchiedarstellungen einige Detailpunkte innerhalb der Hierarchie zunächst hinter Oberpunkten versteckt werden. Erst durch einen Interaktionsschritt, wie beispielsweise das Anklicken eines Oberpunktes, werden die Unterpunkte entfaltet.[19] Hier treten wieder die Hierarchien inhärenten Probleme auf, die durch Karten eigentlich verhindert werden sollten. Geschickter ist es da, auf das Verstecken von Unterpunkten zu verzichten.
Dies wird in einer zweiten Variante getan, den Split Windows. Diese teilen den Bildschirm einfach in zwei Ansichten auf. In der einen Ansicht stellen sie den Kontext dar, also den Überblick über die Gesamtstruktur und in der anderen den Fokus, also die detaillierte Ansicht eines Ausschnittes. Innerhalb des Kontextes wird beispielsweise durch eine Markierung in Form eines Rechtecks der jeweilig sichtbare Teil der Detailansicht hervorgehoben. Die Verwendung dieser Split Windows zwingt die jeweilige Darstellung jedoch wegen der Doppelung der Ansicht in ein noch kleineres Format. Zudem müssen Anwender die Detailansicht in die Kontextansicht übertragen, was einen zusätzlichen kognitiven Aufwand bedeutet.
Eine dritte Variante verbindet Fokus und Kontext in einer Darstellung. Um dies zu erreichen, wird der Kontext um den Fokus herum in der aus der Photographie übertragenen Fischaugen-Technik (›fisheye view‹) angelegt.[20] Dabei wird der Grad des Interesses beziehungsweise der Relevanz direkt mit dem Grad der Verzerrung verbunden. Je relevanter ein Objekt ist, desto größer und somit detaillierter ist seine Darstellung. Bei dieser Form der Darstellung kommt es zu krassen Verzerrungen, die eine Orientierung in ungewohnten Umgebungen stark erschweren und in gewohnten Umgebungen wegen ihrer Andersartigkeit auf Ablehnung seitens der Anwender stoßen.
Das Prinzip der graphischen Verzerrung kann allerdings auch verfolgt werden, ohne daß dabei gegen Sehgewohnheiten verstoßen wird. Um die Verzerrung zu erklären wird die dritte Dimension bemüht. Hierbei steht der Fokus im Vordergrund und der Kontext im Hintergrund. So erscheinen fokussierte Knoten auf natürliche Weise größer als nichtfokussierte. Dieses Darstellungsprinzip ›fokussiert=groß, nichtfokussiert=klein‹ wird auch vom Fisheye View verfolgt. Die unnatürliche Verzerrung des Fisheye Views wird bei dreidimensionalen Darstellungen durch die Einbindung gewohnter räumlicher Seherfahrungen aufgefangen. Kognitive Grundlage für die Einbeziehung der dritten Dimension bildet die menschliche Fähigkeit, die Existenz von Objekten, die durch andere zum Teil verdeckt werden, aufgrund bestimmter Hinweise zu erschließen oder das Wissen um ihre Existenz nicht zu verlieren, auch wenn sich andere Objekte davorschieben. Dieser Vorteil gegenüber dem Fisheye View wird jedoch mit einem krassen Nachteil erkauft: Während der Fisheye View stets sämtliche verfügbare Information gleichzeitig darzustellen vermag, werden beispielsweise bei Conetrees, dreidimensionalen Baumvisualisierungen, oftmals nichtfokussierte Elemente durch fokussierte verdeckt. Der Vorteil der graphische Darstellung gegenüber textuellen Darstellungen, nämlich daß die Bildung eines geeigneten mentalen Modells ermöglicht oder zumindest unterstützt wird, wird beim Einsatz der dritten Dimensionen daher elementar: Das mentale Modell der Darstellung erweitert den sichtbaren Teil zu einem Gesamtbild. Fehler- oder lückenhafte mentale Modelle führen jedoch zu Schwierigkeiten in der Handhabung dreidimensionaler Darstellungen.
Neben der Navigation bietet sich in Hypermediasystemen eine zweite Form des Zugangs an: die Suche. Hier verfolgt der Anwender keine Verlinkungen, sondern er versucht, durch die Formulierung einer Suchanfrage ohne Umwege gezielt zu einem für ihn interessanten Knoten zu gelangen. Diese Vorgehensweise hat sich im Internet als Erstzugang weitgehend durchgesetzt.[21] Um ein noch nicht bekanntes Angebot zu einer Fragestellung zu finden, sucht man die Homepage einer Suchmaschine auf, stellt dort eine Anfrage und sieht sich die einzelnen Knoten an, die in der Ergebnisliste angezeigt werden. Gegebenenfalls wiederholt man die Anfrage leicht modifiziert, um das Ergebnis zu verkleinern oder zu erweitern. Ähnlich kann man bei den meisten Internetangeboten verfahren. Auch hier befindet sich in der Regel eine Suchfunktion, die einen direkten Zugang zu einer gewünschten Information bietet.
Der Vorteil einer Suchfunktion in Hypertextsystemen liegt dabei vor allem in der Geschwindigkeit des Informationszugangs. Während beim Browsen bei jeder Verzweigung Entscheidungen getroffen werden müssen über die weitere Richtung, kann eine wohldefinierte Suchanfrage sofort zum gewünschten Resultat führen. Und genau hier liegt auch die Problematik der Suche: Was ist eine wohldefinierte Suchanfrage?
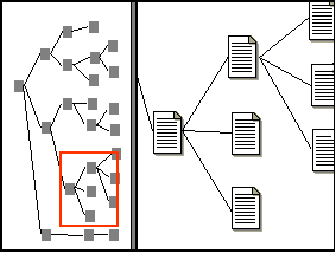
Zur Beantwortung dieser Frage bedarf es zunächst eines kleines Ausflugs in das wissenschaftliche Feld der Suche, dem Dokumentretrieval. Dokumentretrieval beschäftigt sich mit dem Erfassen, Speichern und Wiederauffinden von Information. Im Falle eines Hypertextsystems gilt als Information ein Textknoten beziehungsweise Dokument, welches in bezug auf eine aktuelle Fragestellung von Interesse ist. Abbildung 6 zeigt die prinzipielle Funktionalität des Dokumentretrieval:

Der Kernbereich des Dokumentretrievals ist der Abgleich einer Repräsentation des Informationsbedürfnisses eines Anwenders, also der formulierten Anfrage, mit der Repräsentation in einer Datenbank abgelegter Einheiten, einem Surrogat. Ziel einer Suche ist es, zu einem aktuellen Informationsbedürfnis passende Dokumente zu finden. Idealiter erfüllt das Ergebnis einer Suche zwei Kriterien: Erstens werden alle relevanten Dokumente gefunden und zweitens werden nur relevante Dokumente gefunden. Realiter werden diese beiden Kriterien kaum einzuhalten sein, im Gegenteil: Je mehr relevante Dokumente gefunden werden, desto höher ist stets auch die Anzahl der gefundenen irrelevanten Dokumente. Je niedriger andererseits die Anzahl der gefundenen irrelevanten Dokumente ist, desto weniger der insgesamt vorhandenen relevanten Dokumente werden ausgegeben. In der Retrievalforschung wurden inzwischen verschiedenste Methoden entwickelt, diese Regel abzumildern. Ein Durchbruch im Sinne der Idealvorstellung[23] ist jedoch in der Praxis nicht realistisch.
Grundproblem des Retrievals ist der Umgang mit verschiedenen Behelfskonstruktionen, die zwischen dem Informationsbedürfnis und den Dokumenten stehen. So werden von den Dokumenten Surrogate gezogen, um Speicherplatz und Bearbeitungszeit zu reduzieren. Würde man ohne Surrogate operieren, müßten bei jeder Suchanfrage die kompletten Inhalte der Dokumente durchsucht werden. Die Unmöglichkeit dieser Vorgehensweise läßt sich bei einem Bibliothekskatalog leicht nachvollziehen. Neben dieser technischen Begründung können durch die Verwendung von Surrogaten jedoch auch Formen der Beschreibung gefunden werden, welche die Inhalte der Dokumente formalisiert oder einfach nur präzisiert wiedergeben und so etwaige Zweifelsfälle ausschließen können. In der Informatik hat sich beispielsweise inzwischen das Verwenden von Abstracts bei der Publikation von Artikeln durchgesetzt, da die Verwendung solcher Zusammenfassungen bei der Suche zu durchaus gleichwertigen Ergebnissen führt wie bei der Verwendung von Volltexten.
Dem Surrogat der Dokumente steht auf der anderen Seite eine formalisierte Version des Informationsbedürfnisses gegenüber. Beide Repräsentationen werden miteinander verglichen, und aufgrund dieses Vergleichs fällt das System eine Entscheidung über die Relevanz eines Dokuments in bezug auf das Informationsbedürfnis. Ein solcher Vergleich auf der Metaebene führt zwangsläufig zu Ungenauigkeiten in der Ergebnismenge.[24]
Daneben gibt es auf der Anwenderseite zwei grundlegende Probleme beim Einsatz der Suche. Zunächst ist das Informationsbedürfnis ein sehr vager Zustand, in dem sich der Anwender befindet, wenn er die Suchfunktion aktiviert. Eine genau formalisierbare Beschreibung dieses Informationsbedürfnisses ist kaum möglich, hängt sein Wesen doch von verschiedenen Faktoren ab. So gehen Anwender in der Regel mit einer nur ungefähren Vorstellung an eine Fragestellung heran, die dann im Laufe der Bearbeitung weiter präzisiert wird. Ferner verfügt jeder Anwender über unterschiedliche Vorkenntnisse zur Fragestellung. Was für den einen Anwender tatsächlich eine relevante Information darstellt ist für den anderen Anwender redundanter Datenmüll. Dies wirkt nicht nur bei verschiedenen Anwendern, sondern selbst ein und derselbe Anwender wird nicht zweimal an die selbe Fragestellung mit dem gleichen Vorwissen herangehen. Selbst während der Suche in einer Dokumentdatenbank lernt der Anwender weiter über die Vielfalt der Thematik beziehungsweise über die Vielfalt der dazu erschienenen Publikationen hinzu. Mit diesem zusätzlichen Wissen verändert sich natürlich auch das Informationsbedürfnis.
Die Ungenauigkeit des Informationsbedürfnisses führt
zusätzlich zu einem weiteren Problem: seine Formulierung. Will der Anwender
eine Suchanfrage stellen, so muß er sein Informationsbedürfnis in
einer formalen Anfrage ausdrücken. Hier steht er zum einen vor dem Problem,
dieses vage Informationsbedürfnis nun auf einmal konkret ausdrücken zu
müssen, zum anderen muß er dies zusätzlich in einer formalen
Anfrage tun. Im einfachsten Fall bedeutet das, daß er einige beschreibende
Terme eingibt und das System zu diesen Termen nach bestimmten statistischen
Verfahren eine nach Relevanz geordnete Liste ausgibt. Hier stehen die
relevantesten Dokumente an erster Stelle. Je weiter unten in der Liste ein
Dokument steht, desto weniger paßt es zur Suchanfrage. Diese Form der
Ausgabe wird in Suchmaschinen im Internet in der Regel als »einfache
Suche«, »Expreßsuche« oder »Standard-
suche«
bezeichnet. Komplizierter wird es bei der Verwendung der bei Suchmaschinen oder
auch Bibliothekskatalogen (Online Public Access Catalogues, OPAC) oftmals als
»Profisuche« bezeichneten Booleschen Recherche. Hier können die
Suchterme zusätzlich durch die Booleschen Operatoren UND, ODER und NICHT
sowie durch Klammerungen kombiniert und verknüpft
werden.[25]
Ein einfaches Beispiel soll hier den Unterschied zwischen den beiden Verfahren verdeutlichen. Gesucht werden sollen Texte zur Literaturgeschichte der Klassik. Bei der Expreßsuche wird eine Formulierung der Suchanfrage lauten: »Klassik, Literaturgeschichte«. Zu dieser Suchanfrage werden sämtliche Dokumente ausgegeben, die etwas mit Klassik zu tun haben, die etwas mit Literaturgeschichte zu tun haben oder vielleicht sogar mit beidem etwas zu tun haben. Letztere sollten in der Ausgabeliste an erster Stelle erscheinen.
Bei der Booleschen Recherche, also der »Profisuche«, wird eine Suchanfrage »Klassik UND Literaturgeschichte« lauten und zu Dokumenten führen, die beide Themen behandeln. Ferner können durch die Boolesche Recherche weitere Einschränkungen vorgenommen werden wie etwa bei »Klassik UND Literaturgeschichte UND NICHT Musik«, welche zwar ebenfalls zu Dokumenten führt, die sowohl Klassik als auch Literaturgeschichte behandeln, jedoch nichts mit Musik zu tun haben. So kann die Anfrage ausgesprochen präzise formuliert werden und zu einer kleinen aber sehr aussagekräftigen Ergebnismenge führen.
Voraussetzung dafür ist jedoch, daß der Anwender mit der Booleschen Algebra umgehen kann. Dies scheint auf den ersten Blick einfacher, als es tatsächlich ist. In Wirklichkeit allerdings formulieren selbst professionelle Datenbankrechercheure vielfach fehlerhafte Anfragen. Grund dafür ist zunächst die augenscheinliche Nähe der Booleschen Operatoren zu natürlichsprachlichen Junktionen, die sich bei näherer Betrachtung als trügerisch erweist. So ist beispielsweise das umgangsprachliche ›oder‹ nicht genau definiert: Der Satz »Hans oder Petra hatten die Masern schon.« kann ausschließend heißen, daß entweder Hans oder Petra, also nur einer von beiden, die Masern hatte. Oder er kann einschließend heißen: mindestens einer von beiden, eventuell aber auch beide hatten bereits die Masern. Das Boolesche ODER läßt solche Ambiguitäten nicht zu, sondern definiert sich strikt als einschließend.
Ferner wird der Vorteil der Booleschen Recherche zusätzlich zum Problem: Durch die Möglichkeit der präzisen Anfrage beschäftigt sich der Anwender vergleichsweise lange damit, die Größe der Ergebnismenge zu justieren. Schränkt er die Anfrage zu eng ein, erhält er eine leere Ergebnismenge. Faßt er die Anfrage zu weit, erhält er zu viele Dokumente, als daß er sie noch einsehen könnte.
Um die Probleme im Umgang mit der Suche zu reduzieren, gibt es verschiedenen Methoden, die von recht einfachen Tricks über den Einsatz von Hilfselementen, bis hin zu grundlegenden Designüberlegungen reichen. Zunächst ist es sinnvoll, den Anwender zu einer möglichst genauen Umschreibung seines Informationsbedürfnisses einzuladen. Dies kann schon durch relativ leichte Methoden, wie dem Setzen der Breite einer Eingabezeile, geschehen.
Anwender von Hypermediasystemen generieren zu 80% Suchanfragen, die aus nur einem Begriff bestehen. Dies mag in eng begrenzten Umgebungen noch zu Erfolg führen. Im Internet ist jedoch zuviel Information vorhanden, als daß zu einem einzelnen Suchterm noch eine brauchbare Ergebnismenge geliefert werden könnte. Tatsächlich werden hier zu 80% Suchanfragen mit bis zu zwei Suchtermen gestellt.[26] Auch dies scheint immer noch recht wenig, will man ein Informationsbedürfnis präzise formulieren. Auch wenn es keine ideale Anzahl von Suchtermen gibt, so werden in der Regel dennoch gute Suchergebnisse durch eine Mischung aus weitgefaßten (etwa »Auto«) und spezifischen (etwa »Isetta«) Suchtermen erreicht. Solch eine Mischung ist jedoch nur mit mehreren Suchtermen zu erreichen.
An dieser Stelle steht der Anwender einem guten Suchergebnis selbst im Weg, da er versucht, mit möglichst wenig Suchbegriffen auszukommen. Es ist eine vergleichsweise anspruchsvolle Aufgabe, geeignete Suchterme zu finden, so daß es nicht weiter verwundert, wenn die meisten Recherchen mit ein oder zwei Begriffen durchgeführt werden. Durch geschickte Dimensionierung der Eingabefelder kann dieser Tendenz entgegengewirkt werden. Kurze Eingabefelder, wie sie vor allem bei kommerziellen Internet-Auftritten[27] gerne verwendet werden, ermuntern zu Ein-Wort-Suchen, da die Begrenzung des Eingabefeldes eine Hemmschwelle bildet. Wird das Eingabefeld jedoch größer dimensioniert, so entsteht beim Anwender eher das Bedürfnis, das Feld aufzufüllen.
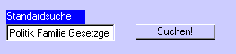

Das Verändern der Größe eines Eingabefeldes mag auf den ersten Blick trivial erscheinen, es ist jedoch ein schönes Beispiel dafür, wie Anwender durch sehr subtile Zwänge in ihrem Verhalten beeinflußt werden können.[28] Anwender scheinen das Bedürfnis zu haben, das Eingabefeld auszufüllen und richten daher die Anzahl ihrer Suchterme weniger nach ihrem eigentlichen Informationsbedürfnis, sondern nach der inhaltlich vollkommen vernachlässigbaren Größe des Eingabefeldes.
Neben solchen noch recht einfach zu implementierenden Aspekten, gibt es noch verschiedene andere Methoden, das Finden von Suchtermen zu fördern. So gehört es inzwischen zum Standard, daß dem Anwender eine Liste mit recherchierbaren Suchtermen zur Verfügung gestellt wird, aus der er geeignete wählen kann. Mitunter wird diese Liste noch zusätzlich in Form eines Thesaurus angeboten. Durch Vorschläge für Synonyme, Ober-, Unter- oder Gegensatzbegriffe wird dem Anwender eine zusätzliche Hilfe bei der Formulierung der Suchanfrage geboten.[29] Die Notwendigkeit des Einsatzes von Thesauri wird schnell deutlich, wenn man im Internet mit Synonymen sucht. So findet beispielsweise die Suchmaschine Fireball zum Term »Waschmaschine« 21.020 Seiten, zum Term »Waschvollautomat« werden 742 Seiten gefunden, bei einer Überschneidung von 253 Seiten (Stand 29.6.2000). Wer also nur nach »Waschmaschine« sucht, findet nicht alle relevanten Seiten. Der Term »Waschvollautomat« ist jedoch vergleichsweise unüblich und wird den wenigsten Anwendern spontan einfallen. Hier hilft die Verwendung eines Thesaurus.
Neben der Auswahl von Suchtermen kann der Anwender aber auch bei der Formulierung der Suchsyntax unterstützt werden. So bietet beispielsweise ein Suchraster eine gute Möglichkeit, Boolesche Verknüpfungen übersichtlich zu organisieren. Zwar kann durch ein solches Raster nicht die gesamte Mächtigkeit der Booleschen Recherche gebunden werden, jedoch sind bereits hier sehr spezifische Anfragen möglich, die das in der Praxis genutzte Komplexitätsspektrum weitgehend abdecken. Tatsächlich werden bei einer Recherche für gewöhnlich Synonyme und ähnliche Begriffe durch eine ODERung zu einem Pool verknüpft. Diese Pools wiederum werden durch UNDungen kombiniert. Ist die Ergebnismenge zu klein, werden die Pools durch zusätzliche ODERungen erweitert. Ist die Ergebnismenge zu groß, werden entweder ODERungen entfernt oder eine zusätzliche UNDung eingeführt. Dieser Strategie kommt das Suchraster entgegen, indem es die entsprechende Struktur räumlich darstellt: ODERungen werden innerhalb einer Zeile ausgedrückt und UNDungen über die Zeilen hinweg. Die in Abbildung 8 formulierte Suchanfrage würde textuell wie folgt lauten: »(Politik ODER Gesetz) UND (Arbeit ODER Beruf) UND Familie«.
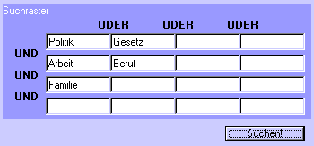
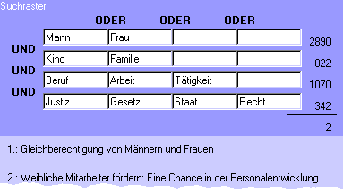
Abb. 9: Suchraster mit direktem Feedback.
[30]
Die Suche von Texten führt in der Regel nicht auf Anhieb zum Erfolg. Meist bedarf es einer Justierung der Suchanfrage oder gar einer kompletten Reformulierung. Während dieses iterativen Prozesses ist es hilfreich, möglichst schnell möglichst viel Information über den Verlauf der Suche zu erhalten. Im Suchraster in Abbildung 8 muß nach der Eingabe der Suchkriterien zunächst der »Suchen«-Button gedrückt werden, daraufhin erscheint die Ergebnisliste.
Diese Vorgehensweise ist in zweierlei Hinsicht suboptimal: Erstens gibt es konzeptuell keinen Grund, weshalb zunächst ein Button gedrückt werden müßte. Dies mag in Internetanwendungen aufgrund der langsamen Übertragungszeiten sinnvoll erscheinen, bei lokalen Suchen allerdings sollte direkt nach der Eingabe eines Suchkriteriums ein Feedback erfolgen. Nur so kann der Anwender bereits beim Aufbau seiner Suche genau informiert werden. Zum anderen wird keinerlei Information zu den Ergebnissen der einzelnen Suchterme geliefert. Selbst bei direktem Feedback wäre hier nicht genügend Information angeboten.
Abbildung 9 (siehe oben) zeigt das gleiche Raster in optimierter Version. Hier wird am Ende einer jeden Zeile angezeigt, wie viele Texte zu der in der Zeile ausgedrückten ODERung gefunden wurden. Zusätzlich wird die Anzahl der nach der UNDung ›unter dem Strich‹ übrigbleibenden Dokumente gezeigt. Da dies im vorliegenden Fall nur zwei sind, ist eine Erweiterung der Suchanfrage wahrscheinlich wünschenswert. Ansatzpunkt wäre die letzte Zeile, da sie am wenigsten Treffer (342) produzierte. Das Suchraster aus Abbildung 8 würde an dieser Stelle keinen weiteren Hinweis darauf geben, wo eine Erweiterung sinnvoll sein könnte.
Auch bei der Standardsuche ohne Boolesche Operatoren kann Feedback die Recherche unterstützen. Am einfachsten geschieht dies als Hinweis auf die Ordnung der Ausgabeliste. Wie oben beschrieben, ist die Ausgabe der Standardsuche nach der Relevanz der gefundenen Texte in bezug auf die Suchanfrage geordnet. Diese Ordnung wird durch verschiedene mehr oder weniger komplizierte statistische Verfahren ermittelt. Es macht zwar wenig Sinn, dem Anwender das genaue Ergebnis dieser Berechnungen vermitteln zu wollen, er wäre sicherlich überfordert, aber eine Umrechnung in Prozente ist ein eingängiges Mittel der Veranschaulichung. Einerseits merkt der Anwender so, daß überhaupt eine Ordnung besteht. Eine einfache Auflistung der Titel würde diesen Hinweis nicht geben. Andererseits kann er gut die qualitative Einschätzung des Systems erkennen. Bewegen sich selbst die obersten Texte der Liste in einem niedrigen Prozentbereich, scheint zu der entsprechenden Suchanfrage kein geeignetes Material vorhanden zu sein. Bewegen sich auch noch Elemente weit unten auf der Liste, nahe der 100%, so kann dies ein Hinweis darauf sein, daß die Suchanfrage eventuell zu weit formuliert wurde. Aber auch in weniger extremen Fällen, in denen die Prozentangaben langsam sinken, geben sie dem Anwender einen Anhaltspunkt.
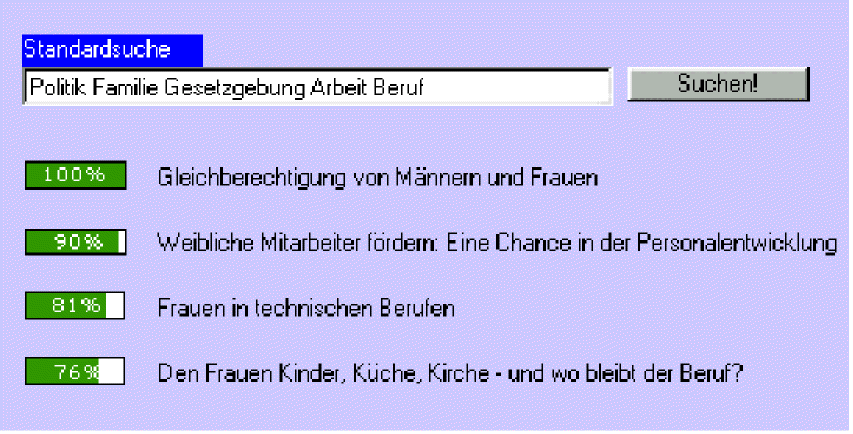
Abbildung 10 bietet nicht einfach nur Relevanz-Feedback in Form von Prozentangaben, sondern visualisiert diese noch zusätzlich durch einen Balken, der ähnlich einer Füllanzeige funktioniert. Visualisierung ist eine gute Möglichkeit, Anwenderprobleme bei der Suche abzumildern. Dabei beschränkt sich die Visualisierung nicht nur auf wenige einfache Hinweise wie in Abbildung 10, sondern kann die gesamte Suche umfassen. Zur Visualisierung der Recherche gibt es inzwischen zahlreiche Ansätze, wie beispielsweise der in Abbildung 11 vorgestellte.[31]
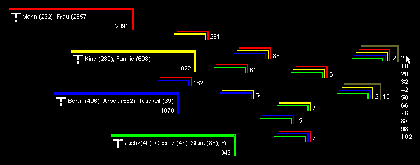
Die hier visualisierte Suchanfrage entspricht der in Abbildung 9 im Suchraster eingegebenen Anfrage. Innerhalb der größeren Winkel werden die einzelnen Suchterme eingegeben und automatisch als ODERung verknüpft. Die übrigen mehrfarbigen und verschachtelten Winkel symbolisieren Kombinationen aus den ODERungen. Gegenüber dem Suchraster konnten die Möglichkeiten der Manipulation und des Feedbacks deutlich erweitert werden. So werden hier nun sämtliche möglichen UNDungen vorgestellt, während das Suchraster nur das Ergebnis der UNDung über alle Zeilen zeigte. Zwischenergebnisse wurden bislang unterdrückt. Hier werden zu jedem Suchbegriff und jeder Kombination die Anzahl der gefundenen Dokumente gezeigt. So können Schwachpunkte der Anfragestellung schnell erkannt werden. Ein einfacher Klick mit der Maus auf die entsprechende Menge genügt, um die enthaltenen Dokumente anzuzeigen.
Ferner schlägt das System eine Gewichtung der Suchbegriffe und der mit ihnen verbundenen Kombinationen vor: Je weiter rechts eine Kombination steht, desto höher ist ihr vom System berechneter Relevanzwert. Gleichzeitig ist dieser Bewertungsvorschlag vom Anwender leicht zu korrigieren, indem er die einzelnen Elemente auf dem Bildschirm hin- und herschiebt. Hier liegt die Kraft von Visualisierungen: Der Anwender kann ohne differenzierte Kenntnis der zugrundeliegenden Algorithmen leicht in die Relevanzbewertung eingreifen.
Schließlich bietet die Visualisierung dem Anwender eine zusätzliche Suchfunktion auf der Basis von bereits gefundenen Dokumenten. Mit ihr können gefundene Mengen ohne eine Reformulierung der Anfrage vergrößert werden. Es werden einfach neue Dokumente ausgegeben, die den bereits gefundenen ähnlich sind. In Abbildung 11 sind zwei Mengen mit jeweils zwei Dokumenten enthalten, die durch eine solche Suchfunktion erweitert wurden. Sie sind an einem zusätzlichen grauen Winkel und einer zusätzlichen Zahl zu erkennen, welche die neue, erweiterte Mengengröße anzeigt. Die eine Menge ist bereits von zwei auf zehn Dokumente erweitert worden, und die andere Menge mit bislang ebenfalls zwei Dokumenten wird gerade erweitert. Eine Klappliste zeigt mögliche Vergrößerungsschritte an.
Die hier beschriebene Visualisierung stellte sich in formalen Anwendertests den textuellen Recherchesystemen als deutlich überlegen heraus. Der Grund dafür dürfte in verschiedenen Punkten liegen, von denen hier zwei exemplarisch herausgegriffen werden sollen. Zunächst bietet die Visualisierung direktes und umfassendes Feedback. Sie gibt detailliert über den Stand der Suche und etwaige Schwachpunkte der Suchanfrage Auskunft. Gleichzeitig werden die recht komplizierten Modelle und Methoden der Relevanzbeurteilung und Ähnlichkeitsberechnung graphisch in eine einfache Form gebracht. Es ist für ihre erfolgreiche Manipulation kein tiefes Verständnis mehr notwendig. Diese beiden Gründe sind elementare Bestandteile der Grundkonzeption der vorgestellten Visualisierung: die Umkehr des Suchprozesses. Der Anwender muß nicht mehr mühsam eine Suchanfrage formulieren, sondern er kann unter vom System generierten Suchanfragen wählen.
Die Visualisierung der Suche ist ein gutes Beispiel, wie Textuelles durch die Einführung einer anderen Modalität optimiert werden kann. Jedoch sind Visualisierungen nicht per se vorteilhaft, sondern können ganz im Gegenteil im Vergleich zur reinen Textform auch nachteilig sein.[32] Von den Bedingungen für die anwenderfreundliche Gestaltung verschiedener Modalitäten soll im folgenden die Rede sein.
Eine ausführliche Beschreibung aller Probleme beim Einsatz verschiedener Modalitäten würde den Rahmen dieses Artikels schnell sprengen. Noch weniger kann hier eine umfassende Darstellung aller Lösungsmöglichkeiten stehen. Es gibt jedoch einige Punkte, die einen Großteil der Problematik in der Praxis abdecken. Statt einer tiefgreifenden Beschreibung softwareergonomischer Konzepte soll hier vielmehr eine Hilfe zur Vermeidung häufig gemachter Fehler geboten werden.
Für die Präsentation von Texten auf dem Bildschirm gelten zusätzlich zu den Regeln der Printprodukte weitere Restriktionen, die im Sinne einer erhöhten Lesbarkeit der Texte wichtig sind. Da sind zunächst rein typographische Aspekte, die aufgrund der Beschaffenheit des Bildschirms neu auftreten. Bildschirme haben in der Regel eine Auflösung von 72 dpi,[33] während handelsübliche Laserdrucker bereits mit 300-600 dpi arbeiten und professionelle Druckereien noch höhere Auflösungen erreichen.
Buchstaben werden am Bildschirm aus einzelnen Punkten zusammengesetzt. Bei einer Bildschirmauflösung von 72 dpi hat ein solcher Punkt eine Größe von 0,35 mm. Eine schräge Linie wird am Bildschirm nicht wirklich als schräge Linie dargestellt, sondern in Form einer Treppe, deren einzelne Stufen 0,35 mm groß sind. Dies ist eine für das menschliche Auge beim Lesen von Text immer noch als störend empfundene Größe. Dieser Treppcheneffekt (vgl. unten Abb. 12) kann allerdings dadurch abgemildert werden, daß der Übergang von Schrift zu Hintergrund nicht hart gestaltet, sondern mit Übergangsfarben abgemildert wird. Dieses Glätten der Schrift wird Anti-Aliasing genannt.
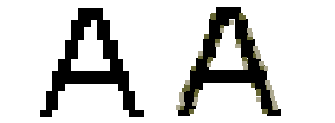
|
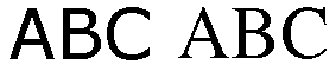
|
|
Abb. 12: Stark vergrößertes ›A‹ ohne und mit Anti-Aliasing. |
Abb. 13: Serifenlose Verdana und Serifenschrift Times. |
Prinzipiell kann man Schrifttypen in Serifenschriften und serifenlose Schriften (vgl. oben Abb. 13) unterteilen. Serifen sind kleine Häkchen an den Buchstaben. Sie dienen zum einen der besseren Unterscheidbarkeit von Buchstaben. So sind die ersten drei Buchstaben des Wortes ›Illusion‹ als Serifenschrift besser zu unterscheiden als in einer serifenlosen Schrift. Zum anderen erhöhen sie die Lesegeschwindigkeit von Texten und vermindern gleichzeitig die Fehleranfälligkeit. Die Häkchen am Boden der Buchstaben bilden für das Auge eine Schiene, entlang derer es sich beim Lesen leiten lassen kann.
Auf dem Bildschirm können Serifenschriften diese Wirkung wegen der geringen Auflösung erst bei einer Schriftgröße von mindestens 16 Punkt entfalten. Bei kleineren Schriftgrößen, wie sie bei den sogenannte ›Brotschriften‹ verwendet werden, also den für den Text verwendeten Schriften, stören Serifen eher. Zusätzlich kann die Lesbarkeit verbessert werden, wenn Schriften mit größeren Mittellängen verwendet werden. Buchstaben mit größeren Mittellängen und entsprechend kleineren Ober- (bei ›b‹) und Unterlängen (bei ›q‹) wirken größer ohne tatsächlich mehr Raum zu beanspruchen und eignen sich daher besonders gut für Medien geringer Auflösung. Während die meisten Computerschriften nicht speziell für Bildschirme entwickelt wurden, sondern nur alte Druckschriften in elektronische Form gebracht wurden, sind von einigen Herstellern mittlerweile speziell für die Lesbarkeit am Bildschirm optimierte Schriften entwickelt worden: Tahoma, Verdana und Georgia von Microsoft sowie Minion und Myriad von Adobe sind Beispiele für solche Schriften.
Die vergleichsweise grobe Rasterung am Bildschirm hat noch weitere Auswirkungen auf die Verwendung von Schriften. So sollte die kleinste verwendete Schrift größer als bei Printprodukten sein und nicht unter 12 Punkt liegen, der Zeilenabstand mindestens 1,5 betragen und die Zeilenlänge 60-80 Zeichen nicht überschreiten.[34] Auch beeinträchtigen zusätzliche Schriftstile wie Unterstreichungen,[35] Fettdruck und Kursivschrift die Lesbarkeit schon im Druck aber noch stärker auf dem Bildschirm.
Aber selbst bei der Verwendung vergleichsweise lesefreundlicher Schriften ist das Leseverhalten bei Printprodukten anders als auf Computerbildschirmen. Zunächst ist die Lesegeschwindigkeit auf herkömmlichen Bildschirmen um 20-40% langsamer. Aber auch die Leseart differiert: Im direkten Vergleich zu gedruckten Texten kann bei der Arbeit am Bildschirm kaum mehr wirklich von Lesen gesprochen werden. In der Regel werden Inhalte eher überflogen. Den vorliegenden Text beispielsweise werden die wenigsten von Anfang bis Ende am Bildschirm lesen. Dazu ist er schlicht zu lang. Üblicherweise werden die Online-Leser den Text überfliegen und versuchen, sich einen Überblick über den Inhalt zu verschaffen. Finden sie eine Textpassage, die ihr Interesse weckt, so werden sie diese Passage genauer lesen, nicht jedoch den gesamten Text. Stellt sich der gesamte Text als interessant heraus, werden die Online-Leser ihn immer noch nicht am Bildschirm lesen, sondern ausdrucken.
Dieses Verhalten ist nicht nur mit der Ermüdung zu erklären, der Augen beim Lesen von Bildschirmen ausgesetzt sind. Es hängt vielmehr mit einigen praktischen Faktoren zusammen, welche bedrucktes Papier dem Bildschirm gegenüber vorteilhaft erscheinen lassen. Prinzipiell eignet sich der Bildschirm schlecht zum Lesen längerer Texte. Er zwingt dem Leser eine starre und unbequeme Haltung auf. Er läßt sich nicht transportieren und eignet sich somit kaum zum Lesen beispielsweise der Nachtlektüre vor dem Einschlafen. Und schließlich kann er nur vergleichsweise wenig Text gleichzeitig darstellen.
Die Beschränkung des zur Verfügung stehenden Platzes stellt beim Bildschirm allerdings ein größeres Problem dar als beim Druck. Bei einem gedruckten Buch etwa blättert man einfach nur eine Seite weiter. Die Dicke der Blätterstapel in der rechten und linken Hand gibt leicht erkennbar Auskunft wo in etwa man sich bei der Lektüre befindet. Auch gibt es generell nur eine sinnvolle Blätterstrategie: Man blättert eine Seite weiter.
Auf dem Bildschirm sieht die Sache etwas anders aus. Im Idealfall würde jedes Textsegment zwar exakt auf dem Bildschirm Platz haben. Entsprechend der Abbildung 14A würden Inhalt und Navigation auf einem Bildschirm Platz haben. In der Realität ist dies jedoch selten zu gewährleisten. Würde man den vorliegenden Text in inhaltlich sinnvolle Segmente zerlegen, so würden sie immer noch nicht auf den Bildschirm passen. Konzeptionell am einfachsten wäre, die Blätterlogik des Buches zu übernehmen. Dann könnten einzelne Segmente auf Bildschirmgröße geschnitten werden und etwa durch einen Button weitergeblättert werden. Allerdings müßte dem Autor dafür die tatsächliche Bildschirmgröße bekannt sein. Mit verschiedenen Auflösungen auf verschieden großen Bildschirmen ist eine Blätterlogik sinnvoll kaum zu realisieren. Ferner stellt sich, was beim Buch selbstverständlich ist, am Bildschirm als wenig intuitiv heraus, da hier keine geeigneten Hinweise über den Fortschritt des Lesens gegeben werden.
Diese Hinweise werden jedoch gegeben, wenn man auf eine Segmentierung verzichtet und den Text in einem Stück auf dem Bildschirm präsentiert, wie es bei den Artikeln der Zeitschrift Forum Computerphilologie der Fall ist und wie in Abbildung 14B gezeigt wird. Eine Scrollbar auf der rechten Seite verdeutlicht, an welcher Stelle im Text sich der Leser befindet. Der Nachteil dieser Vorgehensweise ist, daß Scrollen eine ungeliebte Tätigkeit ist. In der Regel scrollen Anwender nur, wenn sie einen Text gefunden haben, der sie wirklich interessiert. Ansonsten wird nur der Teil gelesen, der ohne Scrollen erreichbar ist.
Im WWW finden sich verschiedenen Versuche, den Anwender vom Scrollen überlanger Texte zu überzeugen. Ein Beispiel dafür ist etwa die Übertragung von Spalten aus dem Zeitungsbereich auf den Bildschirm (vgl. unten Abb. 14C u. 14D). Diese Form der Präsentation steigert die Problematik des Scrollens zusätzlich, indem vom Anwender horizontales Scrollen verlangt wird. Sind die wenigsten Anwender schon bereit, vertikal zu scrollen, so bildet horizontales Scrollen eine ziemlich sichere Methode, Inhalte endgültig unter den Teppich zu kehren.

Wie also könnte nun der vorliegende Text auf dem Bildschirm präsentiert werden? Man könnte den Text entsprechend seiner Überschriften segmentieren, und so den Scrollaufwand zumindest reduzieren. Dies würde jedoch durch einen zusätzlichen Navigationsaufwand teuer erkauft. Geeigneter ist es da, dem Anwender in seinem Leseverhalten entgegen zu kommen und den Text inhaltlich den Anforderungen entsprechend zu gestalten: Wenn Leser am Bildschirm anders lesen als in Büchern, liegt es nahe, daß Autoren auch anders schreiben. Hier hat sich als Empfehlung durchgesetzt, in Anlehnung an das Leseverhalten alle wichtigen Informationen zum Text auf einer Bildschirmseite darstellbar zu gestalten, das heißt Titel, Zusammenfassung und eventuelle zentrale Links sollten ohne Scrollen lesbar sein. Eine ähnliche Vorgehensweise findet sich zum Beispiel auch in journalistischen Publikationen. Hier wird in der Regel ein Artikel durch eine deutlich zu erkennende Zusammenfassung der zentralen Neuigkeit eingeleitet. So kann der Leser sich schnell einen Überblick darüber verschaffen, inwiefern der vorliegende Artikel für ihn interessant ist und dann entweder scrollen oder, was wahrscheinlicher ist, den Artikel ausdrucken.
Bei der Beschreibung der Suche in Hypermediasystemen wurde bereits eine multimediale Komponente eingeführt: die Visualisierung. Sie bietet eine gute Möglichkeit, abstrakte Daten zu veranschaulichen oder riesige Datenmengen leicht interpretierbar und überschaubar graphisch aufzubereiten.[36] In Hypermediasystemen eignen sich Visualisierungen generell gut durch Veranschaulichung der Suchfunktion und der Navigation. Bei technischen Sachtexten kann Visualisierung verwendet werden, um Zusammenhänge, Muster, Trends und Beziehungen zwischen Daten zu verdeutlichen.
Hier treten vor allem die aus traditionellen Sachtexten bekannten Illustrationen in den Vordergrund. Im Rahmen der Lernforschung, die sich wohl am ausgiebigsten mit den methodischen Möglichkeiten von Hypermedia beschäftigt, wurden hier einige interessante empirische Untersuchungen geführt, welche die Vorteile von Hypermediasystemen gegenüber traditionellen Texten zumindest in bezug auf Lernen belegen. So fand die Lernforschung generell einen Vorteil von Hypertext für gezieltes Lernen heraus.[37] Begründet wird dies in der Regel durch den höheren intellektuellen Aufwand beim Navigieren in Hypermediasystemen, der einer schlichten ›Berieselung‹ von herkömmlichen Texten gegenübersteht. Zusätzlich konnte die Lernleistung weiter durch Einsatz von Illustrationen gesteigert werden.[38] Dieser Gewinn wurde auch festgestellt, wenn sich keine neue Information in der Illustration widerspiegelte, sondern ausschließlich im Begleittext behandelte Information graphisch aufbereitet wurde.
Bei den Versuchen zur Verwendung von Illustrationen traten zwei interessante Aspekte zu Tage. Zum einen ist Illustration nicht gleich Illustration. Die Art der Präsentation scheint eine wichtige Rolle zu spielen. Eine einfache Abbildung eines besprochenen Gegenstandes beispielsweise führt zu keinerlei Verbesserungen gegenüber einfachem Text. Werden in die Abbildung zusätzlich Beschreibungen der einzelnen Teile des Gegenstandes eingeführt, verbessert sich das Verständnis leicht. Die deutlichste Verbesserung tritt ein, wenn der Gegenstand und schrittweise seine Funktionsweise und gleichzeitig entsprechende Beschreibungen in Textform in der Illustration gezeigt werden. Ein anderer interessanter Aspekt ist die Kraft, die von Illustrationen ausgeht. So wird bezüglich eines Sachverhalts ein mentales Modell analog zur graphischen und nicht zur textuellen Darstellung aufgebaut. Soll also zur Erklärung eines Textes eine Illustration angefügt werden, so bedarf diese einer genauen Konzeption. Fehlerhafte Illustrationen können durch einen korrekten Text nicht mehr ausgeglichen werden.
Neu am Einsatz von Illustrationen auf dem Bildschirm ist gegenüber traditionellen Printmedien die Möglichkeit der Animation.[39] Aufgrund der realistischeren Darstellung von Bewegung eignet sich Animation besonders gut zur Darstellung von bewegten Elementen. Allerdings kann sich dieser Vorteil unter bestimmten Umständen ins Gegenteil umkehren, da die mitunter lernrelevanten mentalen Prozesse der Simulation vom Computer übernommen werden und keine Eigenleistung des Lernenden mehr erforderlich ist.
Zu bildlichen Darstellungen, seien es Illustrationen, Animationen oder Photographien, gibt es außerhalb der Lernforschung wenig konzeptuelle Richtlinien. Ähnlich verhält es sich mit der Akustik. Hier wurden verschiedene Experimente durchgeführt, die zeigen, daß beispielsweise die Navigation in einer Hierarchie durch akustische Signale verbessert werden könnte. Teilweise kann Akustik auch als alleinige Navigationsform dienen, etwa bei Benutzungsoberflächen für Sehbehinderte.
In der Regel beschränken sich die Empfehlungen jedoch auf technisch motivierte Punkte wie rechen-, speicher- und ladezeitfreundliche Gestaltung. Es wird meist davon abgeraten, Bild und Ton zu verwenden, wenn es sich vermeiden läßt. Werden dennoch Ton- oder sogar Videodokumente verwendet, so sollten diese möglichst komprimiert und in verschiedenen Qualitäten und Größen sowie für verschiedene Abspielprogramme bereitgestellt werden, damit sie problemlos auf verschiedenen Rechnern laufen können.
Neben technischen Ratschlägen betonen verschiedene, meist eher allgemein gehaltene Richtlinien, wie beispielsweise die ISO 14915[40], die Wichtigkeit einer adäquaten Auswahl der Modalitäten. Diese Auswahl richtet sich zunächst nach der umzusetzenden Information. Verschiedene Informationstypen fordern für sich verschiedene Präsentationsformen ein. So kann beispielsweise der Aufbau eines Fahrrades sehr gut durch eine statische Illustration, eventuell eine im Modellbau gerne verwendete sogenannte ›Explosionszeichnung‹, gezeigt werden. Die Funktionsweise des Fahrrades, also die Kraftübertragung vom Pedal zum Hinterrad, kann in einer statischen Illustration nur suboptimal dargestellt werden. Hier muß vom Betrachter ein mentales Abbild konstruiert werden, in welchem er die Bewegung vor seinem geistigen Auge simuliert. Günstiger ist da die Präsentation in Form einer Animation, wobei die mentale Last der Umsetzung der Bewegung vom Computer übernommen wird.[41] Die Erklärung eines Reifenwechsels wiederum kann in verschiedene Zwischenschritte umgesetzt werden, wobei jeder Schritt als Illustration dargestellt ist, in der die zentrale Veränderung zum vorhergehenden Schritt graphisch verdeutlicht wird.
Neben der Umsetzbarkeit von Information bildet die Rezeption durch den Anwender ein zweites elementares Designkriterium. Wichtige Informationen sollten redundant und parallel codiert werden, das heißt über mehrere Modalitäten vermittelt werden. Ein Beispiel für solches Vorgehen sind die durch Abbildungen unterstützten textuellen Erklärungen des vorliegenden Artikels zur Darstellung von Hierarchien. Dabei ist natürlich wichtig, daß die verschiedenen Modalitäten nicht miteinander in Konflikt geraten, also bildlich etwas anderes ausgedrückt wird als textuell.
Konfliktpotential besteht auch im umgekehrten Fall, wenn eine einzige Modalität verwendet wird, um zwei Informationen gleichzeitig zu transportieren. Während man beim Autofahren problemlos den akustischen Verkehrsfunk und die optische Geschwindigkeitsanzeige gleichzeitig verfolgen kann, brächte eine gleichzeitige Präsentation beider Informationen über akustische Signale große Verständnisprobleme mit sich.
Schließlich ist die Präsentationsform stark situationsbedingt. So ist generell eine akustische Umsetzung geschriebenen Textes von Vorteil, da auch blinde Anwender miteinbezogen werden können.[42] Diese Umsetzung sollte allerdings optional abschaltbar sein und auf Inhalte Rücksicht nehmen können. Ein sprechender Geldautomat beispielsweise ist zwar für blinde Anwender wünschenswert, für sehende allerdings zunächst nur ein Kuriosum und bei der akustischen Anzeige des Kontostandes sehr schnell eine Peinlichkeit.
Maximilian Eibl (Berlin)
Dr. Maximilian Eibl
GESIS-Außenstelle
Am Schiffbauerdamm 19
10117 Berlin
eibl@berlin.iz-soz.de