STEPHAN MOSER/PETER STAHL/WERNER WEGSTEIN/NORBERT RICHARD WOLF (HG.): MASCHINELLE VERARBEITUNG ALTDEUTSCHER TEXTE V. BEITRÄGE ZUM FÜNFTEN INTERNATIONALEN SYMPOSION WÜRZBURG 4.-6. MÄRZ 1997. TÜBINGEN: NIEMEYER 2001.
Der vorliegende Sammelband Maschinelle Verarbeitung altdeutscher Texte V dokumentiert zwanzig Beiträge, die im Jahr 1997 auf dem Fünften Internationalen Kolloquium zur Maschinellen Verarbeitung altdeutscher Texte am Institut für deutsche Philologie der Universität Würzburg vorgetragen und im Anschluss daran für die Publikation aufbereitet wurden. Der Sammelband steht in einer Tradition von Kolloquiumsberichten, deren erster Band 1971 erschienen ist. Versucht man, den thematischen Rahmen der beiden letzten Bände (1991 und 2001) zu charakterisieren, dann sind vor allem drei Bezugspunkte prominent:
• der Gegenstandsbereich: altdeutsche Texte (vor allem althochdeutsche, mittelhochdeutsche, frühneuhochdeutsche) und benachbarte Gebiete,
• die jeweils aktuellen Möglichkeiten des Computereinsatzes und der Computerunterstützung in den Sprach- und Literaturwissenschaften,
• Anlage, Stand und Probleme wichtiger Arbeitsvorhaben und Projekte im Gegenstandsbereich, vor allem in den Bereichen der Editionsphilologie, der Lexikographie, der Grammatikschreibung und der computergestützten Textanalyse.
Vergleicht man die beiden Bände Maschinelle Verarbeitung altdeutscher Texte IV (1991) und Maschinelle Verarbeitung altdeutscher Texte V (2001), dann zeichnet sich eine wichtige Tendenz in der EDV-Nutzung ab: neben die Funktion der Computer als Hilfs- und Arbeitsmittel, mit denen Forschungsergebnisse erzeugt werden, tritt nun verstärkt auch die Funktion von EDV-Umgebungen als Mittel der ›Präsentation‹ von Forschungsergebnissen, zum Beispiel im Bereich der Textedition (Beitrag von Boggs/Gärtner/Lenders), der Wörterbucharbeit (Beiträge von Plate/Recker; Lemberg) oder der Namenkunde (Beitrag von Korten/Prinz).
Aktualitätsbesorgnisse in Bezug auf den Band (Kolloquium 1997, Sammelband 2001) haben sich schnell zerstreut. Auch wenn die Entwicklungen in der Computer- und der Softwaretechnik nicht stehen bleiben, so sind grundlegende konzeptionelle Vorstellungen in den Bereichen der Computerphilologie doch sehr viel dauerhafter, und gute Ideen von 1997 sind auch 2001/02 wertvoll. Hinzu kommt, dass die Gruppe der Nutzerinnen und Nutzer von Computern für sprach- und literaturwissenschaftliche Aufgabenstellungen auch zur Stunde (März 2002) noch sehr heterogen ist; es ist deshalb bei der Anlage neuer Projekte äußerst hilfreich, konzeptionelle Überlegungen, technische Entscheidungen und Erfahrungen bereits laufender oder schon abgeschlossener Projekte zu kennen. Viele Beiträger haben im Vorgriff den Schwerpunkt ihrer Darstellung eher auf prinzipielle Aspekte gelegt und technische Einzelheiten zumeist mit Blick auf Nachahmbarkeit und Anwendbarkeit auch in mittelfristiger Zukunft erläutert. Den Beiträgen des Bandes sind teilweise Internetadressen beigegeben, die auf laufende Informationen zum Stand von Projekten verweisen.
Um den Punkt mit den ›guten Ideen‹ zu verdeutlichen, möchte ich drei Beispiele herausgreifen. Im Beitrag von Thomas Klein (Vom lemmatisierten Index zur Grammatik) geht es »um Wege, die von maschinenlesbaren Texten zu einer Grammatik auf der Grundlage dieser Texte führen« (S. 83). Auf diesem Weg wird unter anderem auch die Idee skizziert, wie man Elemente eines Textkorpus im Hinblick auf eine zukünftige grammatische Darstellung kodieren kann. Hierfür wird das Paragraphengerüst einer vorhandenen grammatischen Darstellung als »provisorische Ordnungsinstanz« benutzt, die gegebenenfalls modifiziert wird (S. 98): einem Textelement wird bei der Kodierung eine oder mehrere Paragraphennummern der vorhandenen Grammatik zugeordnet, wobei die Paragraphennummern als eine Art von Adresse für eine grammatische Systemstelle fungieren, die in der neuen Grammatik möglicherweise anders oder auch woanders behandelt wird. Diese Idee ist wertvoll in ganz unterschiedlichen Gebieten der sprachlichen Beschreibung, weil sie den Umgang mit zwei Hauptschwierigkeiten bei der empirischen Beschreibung erleichtert:
• den Umgang mit der großen Zahl von Korpuselementen,
• den Umgang mit der Komplexität von Gegenstandsbereichen und von Ergebnisdarstellungen, zum Beispiel in einer Grammatik oder in einer Wortschatzdarstellung.
Ein zweites Beispiel: Im Beitrag von Wolfram Schneider-Lastin (Erfassung, Verwaltung und Verarbeitung strukturierter Daten) wird der Einsatz von TUSTEP-Masken, die seit 1996 im Programmpaket von TUSTEP verfügbar sind, in geisteswissenschaftlichen Projekten beschrieben, in denen strukturierte Daten eine Rolle spielen, also zum Beispiel Projekte, in denen Bibliographien, Repertorien oder auch Wörterbücher erstellt werden sollen. Auch unabhängig von der technischen Umsetzung in TUSTEP sind die konzeptionellen Hinweise auf die von der Programmumgebung projektspezifisch erzwungene Einheitlichkeit der Daten und auf die Möglichkeit, Prüfkriterien für korrekte Eingaben einzurichten, von hoher Bedeutung für alle Projekte, in denen mehrere Personen über längere Zeit, gegebenenfalls sogar an unterschiedlichen Orten arbeiten:
Schon jetzt aber wird erkennbar, dass den neuen TUSTEP-Möglichkeiten eine wesentliche Bedeutung bei der Zusammenarbeit von Forschergruppen auf nationaler wie internationaler Ebene zukommen kann. (S. 303)
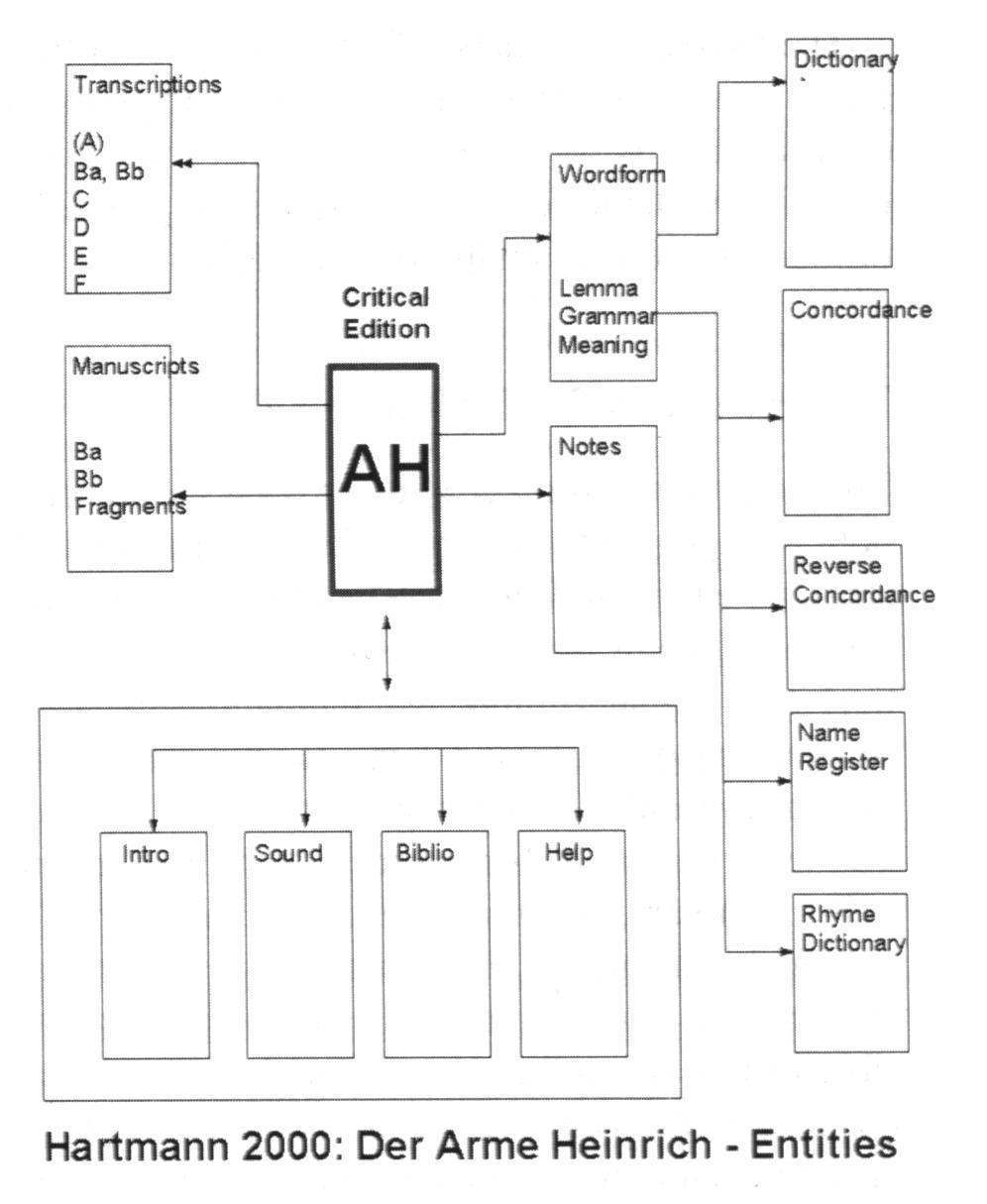
Ein drittes Beispiel ist der Beitrag von Roy A. Boggs, Kurt Gärtner und Winfried Lenders über das Hartmann 2000 Project. In gewissem Sinne führt dieser Beitrag zahlreiche Ideen und Fragen zusammen, die im Lauf der langen Diskussion über den Einsatz von Computern im Bereich der Edition älterer Texte vorgebracht wurden, zum Beispiel die Frage nach dem Zusammenhang kritischer Texte zu ihrer handschriftlichen Überlieferung und zur Variation innerhalb der Überlieferung, die Frage nach unterschiedlichen Darbietungsweisen von Texten (kritischer Text, Transkription einzelner Handschriften, Abbildungen der Überlieferung), die Idee einer Hypertextumgebung mit der Möglichkeit nutzerorientierter Lesepfade (»Change the user, and you change the information«, S. 213) und so weiter. Der Beitrag skizziert ein komplexes editorisches Informationssystem, das für Forschung und Lehre gleichermaßen wertvoll ist. Im Mittelpunkt steht der kritische Text des Armen Heinrich, von dem aus ein Netz von Verknüpfungen zu den Abbildungen der Handschriften führt beziehungsweise führen soll, zu Transkriptionen der Handschriften, zu einem Wörterbuch, zu einer Konkordanz, zu grammatisch-morphologischen Informationen, zu einem Reimverzeichnis, zu einer rückläufigen Konkordanz, zu weiteren Registern, zu einer Bibliographie, zu Anmerkungen und so weiter. Hier eine Skizze der Architektur aus dem Band (S. 216):
Soweit ich sehe, ist dieses Projekt bisher allerdings nicht oder noch nicht auf CD-ROM erschienen, sondern als im Ausbau begriffene Hartmann von Aue Knowledgebase auf der Homepage von Roy A. Boggs erreichbar (<http://www.fgcu.edu/rboggs/hartmann/> (14.8.2002)).
In vergleichbarer Weise sind nicht nur ›Ideen‹, sondern auch wertvolle Projekterfahrungen in den einzelnen Beiträgen enthalten, zum Beispiel die Erfahrungen bei der Retrodigitalisierung der älteren Bände des Deutschen Rechtswörterbuchs (S. 145, Fn. 13). Vor vergleichbaren Problemen stehen heute viele Wörterbuchunternehmungen, und es ist äußerst hilfreich zu erfahren,
• welche Technik verwendet wurde (OCR, dann Umsetzung von Schriftartenkennzeichnungen in lexikographische Feldstrukturen über wiederholte Makro-Durchläufe, »zum Teil aber auch mit händischen Korrekturen«, ebd.),
• welcher Zeitaufwand damit verbunden war,
• wer die Erfahrung gemacht hat und an wen man sich möglicherweise für weitere Auskünfte wenden könnte.
Ein Sachverzeichnis fehlt dem Band allerdings. Es wäre ein sehr wertvolles Hilfsmittel gewesen, einzelne Fragestellungen zu verfolgen, die quer zu den Beiträgen liegen, zum Beispiel Retrodigitalisierung, Prinzipien der Korpusbildung, TUSTEP, Einsatz elektronischer Faksimile-Dateien und Ähnliches.
Nun eine kurze Übersicht zu den einzelnen Beiträgen, die im vorliegenden Rahmen nur stichwortartig sein kann. Der Band umfasst fünf Unterabschnitte: »Einführung«, »Korpusfragen«, »Lexikographie«, »Einsatz neuer Medien«, »Workshop zur Textdatenverarbeitung«.
Nach einem Vorwort der Herausgeber (S. VII-IX) folgt als Einleitung der Beitrag von C. M. Sperberg-McQueen (Die Hochzeit der Philologie und des Merkur: Philologische Datenverarbeitung, S. 3-22). Zentraler Gegenstand sind formale Modelle für Texte und Textelemente, unterschiedliche Konzeptionen für ihre Auszeichnung (zum Beispiel SGML) und einige Probleme von Markup-Umgebungen. Hervorzuheben sind hier besonders die Probleme der Überschneidung von Markierungen (S. 20f.) und Probleme der Behandlung seltener Textstrukturen (S. 21f.) in SGML.
Der Abschnitt »Korpusfragen« umfasst vier Beiträge von Christiane Pankow (Aufbau und Auswertung eines Korpus deutscher und russischer TV-Nachrichten aus der Zeit zwischen 1988 und 1992), Lou Burnard (British National Corpus), Heinrich Hettrich (Rigveda-Korpus als Grundlage für eine vedische Kasussyntax) und Thomas Klein (mittelhochdeutsches Textkorpus als Grundlage für eine neue mittelhochdeutsche Grammatik). Der Beitrag von Lou Burnard über das British National Corpus erinnert im Zusammenhang eines Bandes über die maschinelle Verarbeitung altdeutscher Texte daran, dass es an der Zeit wäre, die Frage nach einem historischen Nationalkorpus für das Deutsche und seine Varietäten vor dem Hintergrund dieser Erfahrungen erneut zu stellen.
Der Abschnitt »Lexikographie« umfasst zunächst vier Beiträge zur EDV-Unterstützung bei einzelnen Wörterbuchprojekten: beim Lexikon der Namen in literarischen Texten des Mittelalters (Friedhelm Debus), beim Deutschen Rechtswörterbuch (Ingrid Lemberg), bei der Wigalois-Konkordanz (Yoshihiro Yokoyama) und beim neuen Mittelhochdeutschen Wörterbuch (Ralf Plate und Ute Recker). All diesen Projekten ist gemeinsam, dass die lexikographische Arbeit auf großen Textkorpora aufruht und dass die Artikel deshalb auch wertvolle Informationen zu Aufbau und Umgang mit Korpora enthalten. – Ein weiterer Artikel beschreibt Forschungen und Lehre zum Mittelhochdeutschen in Japan und bespricht vor diesem Hintergrund die Konzeption eines mittelhochdeutschen-japanischen Wörterbuchs, das 1991 erschienen ist (Yoshihiro Koga). – Hinzu kommen zwei Artikel von Paul Sappler über die Herstellung umfangreicher Register und von Stefan Moser über die Architektur einer Datenbank zur frühneuhochdeutschen Wortbildung (Substantivableitungen). Beide Artikel entstammen spezifischen Projekten, sie enthalten über den engeren Projektbezug hinaus aber auch zahlreiche konzeptionell wertvolle Überlegungen und Erfahrungen, zum Beispiel die Unterscheidung von ›Sichtweisen‹ auf Registereinträge: vom Gegenstand her; von den Formulierungsvorgaben des Registers selbst her; von unterschiedlichen Benutzerbedürfnissen her (S. 150 und S. 158).
Der Abschnitt »Einsatz neuer Medien« umfasst vier Beiträge. Der Artikel von Ulrich Müller und Andreas Weiss skizziert den Weg des Salzburger Neidhart-Projektes von der EDV als Editionswerkzeug zur Nutzung der EDV als Präsentationsmedium einer digitalen Edition im Internet. In vergleichbarer Weise beschreibt auch Andrea Rapp eine Mehrfachfunktion des EDV-Einsatzes: als Werkzeug der Vorbereitung gedruckter Teileditionen; als Werkzeug für die sprachwissenschaftliche Untersuchung; als Präsentationsmedium digitaler Editionen (mittelfränkische Urkunden des 13./14. Jahrhunderts). In diesem Abschnitt steht auch der oben schon erwähnte Artikel von Boggs, Gärtner und Lenders zum Projekt Hartmann 2000, und auch hier ist eine Art Medienverbund zu erkennen, der gedruckt publizierte Teile (kritische Edition) und digitale Teile umfasst. In einem weiteren Artikel beschreiben Heinz Korten und Michael Prinz einen Prototypen für ein multimediales Namenbuch.
Der abschließende Teil »Workshop zur Textdatenverarbeitung« dokumentiert Beiträge, die unterschiedliche Arbeitsweisen und Anwendungsmöglichkeiten des Tübinger Programmpakets TUSTEP (zur Einführung: Beitrag von Wilhelm Ott, S. 265ff.) veranschaulichen: die Herstellung einer synoptischen, mehrsprachigen Ausgabe eines Textes und seiner Übersetzungen als Grundlage für den Übersetzungsvergleich und die Übersetzungskritik (Derek Lewis, Peter Stahl); der oben schon erwähnte Einsatz von TUSTEP-Masken in Projekten, die strukturierte Daten im weitesten Sinne verarbeiten (Wolfram Schneider-Lastin); und Verfahren der Apparaterstellung auf der Grundlage automatischer Textvergleiche (Wilhelm Ott). Den Beiträgen dieses Abschnitts sind teilweise detaillierte Programmierbeispiele beigegeben. – Hinweise zu TUSTEP-Anwendungen sind auch in mehreren anderen Beiträgen des Bandes zu finden, zum Beispiel in den Beiträgen von Hettrich, Koga, Sappler, Yokoyama, Plate/Recker und Rapp. Auch hier hätte ein Sachregister den Zugriff erleichtert.
Zusammenfassend: Der Band ist reich an Ideen, Erfahrungen und konzeptionellen Modellen für Projekte ganz unterschiedlicher Art, zum Beispiel Textkorpora, Grammatiken, Wörterbücher, Editionen, Untersuchungen. Der Band dokumentiert auch eine Entwicklung, die keineswegs abgeschlossen ist: die Nutzung von Computern nicht nur als Arbeitsmittel, sondern auch als Präsentationsmedium für Texte und für die Früchte der Arbeit an ihrer Erschließung.
Thomas Gloning (Marburg)
PD Dr. Thomas Gloning
Philipps-Universität
Fachbereich 09
Institut für Germanistische Sprachwissenschaft
35032 Marburg
gloning@mailer.uni-marburg.de