THE PEARL-DIVER MODEL. THE HYPERNIETZSCHE DATA MODEL AND ITS CACHING SYSTEM
Abstract
During its early stages in the first months of 2002, HyperNietzsche was a conventional web application, using a script language to generate dynamic web pages ›on the fly‹ through a relational database. When Net7[1] joined the project, in April 2002, we faced a rapidly growing database, a user interface that changed frequently and, most noticeably, a very complex mechanism of visualizing relations among contents called ›dynamic contextualization‹. The main concern was not the quality of code but rather the inadequacy of the architectural model. So, during 2002, we developed a new model called Pearl-Diver Model (PDM). This document contains a short and accessible description of the architectural changes that have taken place during the transition to the new architecture. For a more detailed formal analysis see the HyperNietzsche developers website at <http://www.hndevelopers.org> (19.2.2004).
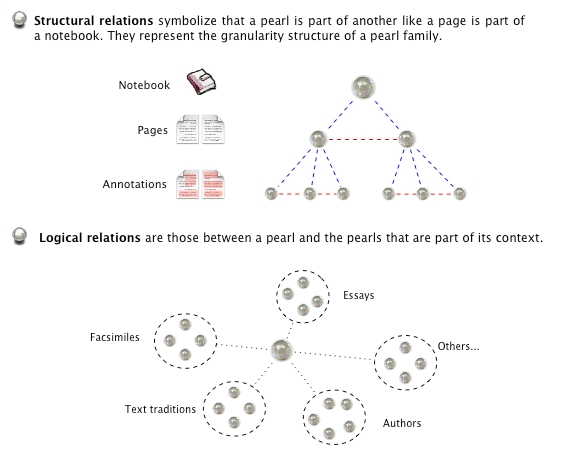
To handle the complexity of the project we adopted our own terminology: we use the term pearl instead of the usual Computer Science term ›object‹. HyperNietzsche is a project that deals with pearls and their relations. Pearl is the abstract term to designate all the elements that together make up Friedrich Nietzsche's work: papers and books, manuscripts and letters, Nietzsche's private library and biographical documents. With the term pearl we also indicate every contribution that other authors wrote about Nietzsche (critical essays, translations, but also transcriptions of manuscripts and critical editions). The ›pearls‹ HyperNietzsche deals with are divided into ›sub-pearls‹, and each ›sub-pearl‹ is a pearl in itself. The ›sub-pearls‹ can be divided themselves and so forth as long as each pearl can be studied in itself. The HyperNietzsche Team calls this structure »granularity«. The granularity tree can be seen as a yardstick that measures the deepness of a pearl. Each pearl is related to other ›pearls‹ and these relations can be of different types. Relations are called »structural« when they symbolize that one pearl is physically part of another, like a page is part of a notebook. Structural relations are used to represent granularity trees. Relations are called logical when they represent abstract links between ›pearls‹. Logical relations are the basis the of dynamic contextualization relies on. They are links that can be followed in both directions. If you examine a traditional HTML link you see that it contains information concerning its target. But think about what happens when you follow the link and reach the target: you have lost all the information about your starting point. The dynamic contextualization obviates this behavior.
Handling these structures increases the complexity and the sheer amount of data the HyperNietzsche Project has to deal with. It suffices to imagine how much material Nietzsche has written and how many sub-parts this material may contain to have an idea of how complex all this can be. Let us add to the count all the contributions that have been and will be written about Nietzsche's materials. Of course it is possible to design a system that is able to store and process this amount of information by developing a conventional web application. It was just what the first team of computer scientists of HyperNietzsche began to do. They built HyperNietzsche as a dynamic Hypertext. This meant that the content of the pages shown by the browser was not statically stored on the server's filesystem (as HTML files), but was built on the fly querying a relational Database, which was constantly updated.
During the development of the first version of HyperNietzsche, it became clear that such a system would be quite clumsy and unable to respond quickly enough to users' requests. To explain this point it is necessary to explore the technical structure of the system in more details. Information about ›pearls‹ is stored in the database tables. ›Pearls‹ that share similar characteristics are stored in the same table. When the information about one pearl, say page 3 of Nietzsche's manuscript N IV 2, is requested by the user, the system searches the manuscripts' table to locate manuscript N IV 2, then follows the relation »manuscript-page« to find the right pearl. The process does not end here, as the contextualization information must be retrieved. The context of a pearl is the set of contributions that refers to the pearl itself as the object of study. To retrieve the contextualization information we need to follow the »contribution-material relations« from our pearl up to each contribution. Meanwhile, we search for the authors of each contribution, which are contained in the »contribution-author« relation table.
However, this architecture reaches its limits when the structure of the relations amongst the data becomes particularly complex. Considering that the data structure used for representing the dynamic contextualization is an oriented multigraph, a lot of queries to be executed have a high level of complexity[2]. This is unacceptable for a web application, because in certain cases a user will have to wait too long before being able to access the required page.

In order to solve this problem we have developed a new architecture: The Pearl-Diver Model (PDM) that exploits the low volatility of our data. As disk space is cheap and computational time is the scarce resource, we choose to adopt a model that privileges efficiency instead of saving disk space. It is, in fact, a caching mechanism based on XML. The considerations that gave birth to this concept are:
• Many elements of HyperNietzsche are static: they do not change in time. In the old architecture, even static object information was recalculated every time it was requested. This led to a great loss of time. If an element is static we need to process the information just once and then store it somewhere, ready to be delivered to the user. But our elements are not always static. They change when a new contribution is submitted, deleted or modified by an author. When this happens, the contextualization of the referred pearl must include the new contribution, and the information related to the pearl must be processed again. Pre-calculated units of information are called »Presentation«. They are the way that pearls ›present themselves‹ to the outside world.
• Another characteristic of HyperNietzsche is that submitted contributions are not immediately accepted by the system. They must pass the Peer Review scrutiny and wait at least fifteen days to be published. Once accepted, they can be published; this means that their information will be processed. Thus, we can choose a time of the day, usually with low user traffic, and compute every change at once.
• We wanted to retain data security, integrity and consistency from the old system. And we needed to maintain the internal system data structure used to elaborate changes.
• Static, pre calculated information about pearls must be stored somehow. This gave us the occasion to use the XML standard in our project, giving the possibility to export HyperNietzsche pearls to other systems or to expose their metadata in standard formats to be compliant to different specifications.
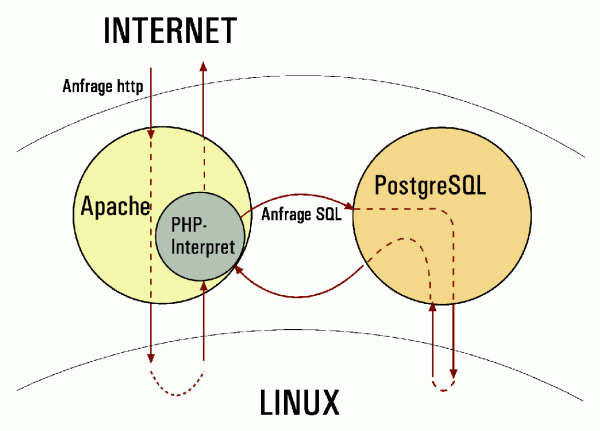
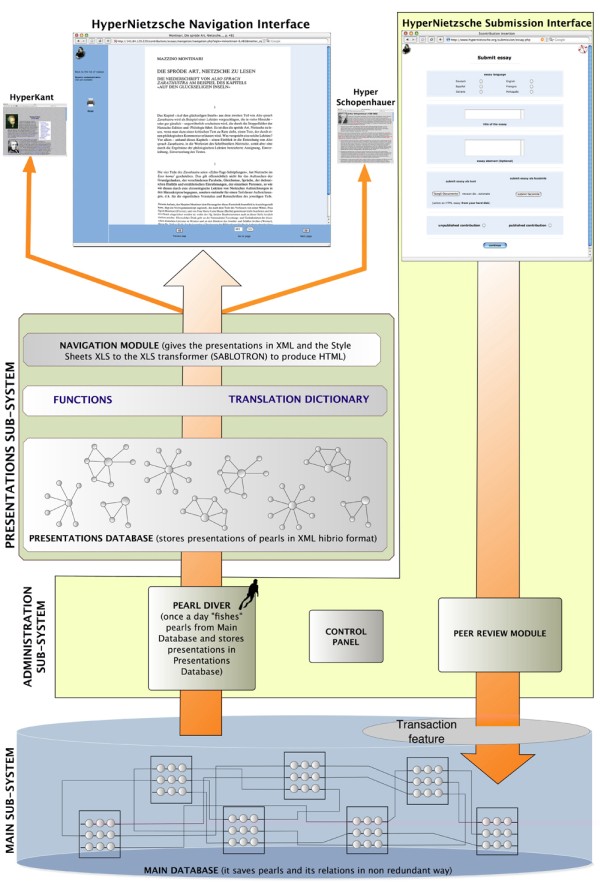
The new architecture consists of three logical sub-systems: The Main Sub-System contains all the information about HyperNietzsche's pearls and relations. All data is stored in a PostgreSQL database following all database data normalization rules. The table's structure and control functions guarantee that data insertion, deletion or update operations are executed without errors or data integrity losses. The Main Sub-System's database is called the Main Database and is physically isolated. It does not serve the user directly but it is used to create Presentations whenever required. This system communicates with the Presentations Sub-system via a module of the Administration Sub-System called Pearl-Diver, as it ›fishes pearls‹ from the Main Database. The process of computing new Presentations is, as in the old architecture, quite time-consuming, but is done only once for every update and not at every user request. Additionally, computation is limited to those pearls directly involved in the update.
The Presentation Sub-System stores Presentations built by the Main Sub-System and provides XML output. The Presentation's XML follows worldwide open-access specifications, hence the platform is usable as an open database or as a stand-alone Internet application. All the Presentation's data are stored in the Presentation's database, which also contains the »Functions« used to generate the final XML. This database doesn't handle data consistency or redundancy. The Main Sub-System handles these issues. Data is stored to make the retrieval of information as fast as possible. To fulfill user requests this database searches just one table. In the most complex cases it searches two tables.
XML presentations can be read by any system and attached to different graphical interfaces. Our platform provides of course its own user interface that is realized using an open-source XSL transformer (Sablotron), which generates HTML pages from XML and XSLT files. The XSLT style sheets contain the instructions about how the XML has to be transformed. Between the Presentation's XML and the user interface, there is the Navigation Module. This module receives the user's request, asks for the corresponding XML to the Presentation's database, and then passes it bundled with the chosen XSL style sheet to Sablotron to build the final HTML page.
Another task that has been assigned to this sub-system is the handling of translations. HyperNietzsche is designed to be accessed by users from anywhere in the world. Each interface page is written in an internal language made of ›identifiers‹. A user entering HyperNietzsche must choose a language. If, for any reason, this is not done, the system reverts to German as default language. Once a navigation language is chosen, identifiers are substituted by words in the chosen language. The identifiers are written in an internal language similar to English, and they will remain invisible to the end-user. Identifiers are used as placeholders. They have meaningful names solely to make it easier for the HyperNietzsche Team to handle them. Translators determine, for every language, which word must substitute each identifier. A specialized navigation interface is available for translators to translate words while navigating HyperNietzsche, in this way they have a clearer idea of the context in which a word appears. This feature is called »Contextual Translation«. The Translation Dictionary is stored in tables within the Presentation's database. These tables are used when pages are created, thus it is faster to have the Translation Dictionary and Presentation in ›the same place‹.
Apart from the Pearl-Diver Module described in 2.1, the Administration Sub-System handles the submission procedures of contribution and Peer Review and provides a Control Panel usable by the project leader and by the system administrators to set system parameters.
The Peer Review Module has the task of supervising the policy of contribution acceptance. It includes an interface used to examine submitted contributions, to vote on them and to write reports. The system checks once or more times a day if a contribution fulfills the publication requirements. Every contribution that passes this check is ›handed over‹ to the Main Sub-System where the necessary Presentations are processed. To submit a contribution there is a dedicated interface that allows the user to send to HyperNietzsche all the required data in a simple, user-friendly way. This interface is also part of the Administration Sub-System. Its task is to save the contribution that will be processed by the Peer Review Module. Contributions are submitted anonymously to guarantee fairness during voting.
Let us assume that a user submits a new contribution. After the approval of the Peer Review, all the pearls cited by this example contribution are scheduled for re-elaboration. Why do we have to re-elaborate all the pearls? Let us suppose that this contribution is an essay about page 3 and 4 of the N IV 2 notebook. The Presentations of the pearls that represent the two pages have, as part of their information, the list of the contributions that cite those two pages. This information is now going to be incorrect because we are adding a new contribution to the list. Every pearl that has to be modified is called ›dirty‹, and is scheduled in the Main Database for its Presentation's re-elaboration. Once a day, the Administration Sub-System calls for the Pearl-Diver Module of the Main Sub-System, which substitutes all the old Presentations marked as ›dirty‹ with their new Presentations, as processed by one of the Main Database internal functions.
Every operation in the Main Database relies on a database feature called Transaction. This feature enables a set of operations to be either entirely completed or entirely failed[3]. Transactions assures that there cannot ever be incongruou information in the Presentation's database. Transactions are used for every query on this database.
Now the Presentation's database contains the Presentation of the new contribution. Presentations are stored in a hybrid format composed of a mixture of XML and raw data, which cannot yet be used by external applications, but allows efficient internal operations. If a user asks HyperNietzsche's interface to show him a contribution, the request is handled by the Navigation Module of the Presentation's Sub-System. After this step the module asks for the information in XML format. The requested valid XML is built out of the Hybrid-formatted data. This process is done by the Presentation's database internal functions. Finally, the interface page about the contribution is shown on the user's browser. Please note that the most time consuming operations are automatically done by the system before any user request. The user has to wait only for the Presentation's database to provide pre-calculated information, which is a very small amount of time.
The Pearl-Diver Model is faster and more efficient than the old conventional architecture. It assures data security, consistency and integrity while at the same time storing enough information to represent all the complex relations between pearls. It also features a built-in interoperability with other applications. This is the direct result of being able to use the XML as a channel between data and interface. Another important advantage that this new design offers is that the core system is clearly separated by its interface. It means that the core system provides an easy and compatible access to its data from outside applications. The raw data obtained from the core system could be used by another interface or as an input for other applications. In this way it is possible to build a meta-hyper able to act as an abstraction layer over platforms dedicated to different authors and also in compliance with protocols like OAI-PMH[4].
Michele Barbera/Riccardo Giomi
NET7 SNC
Via marche, 8a
I-56100 Pisa
http://www.netseven.it/homeing.htm
barbera@netseven.it
giomi@netseven.it