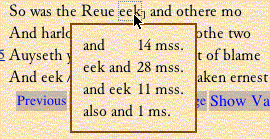
WHERE WE ARE WITH ELECTRONIC SCHOLARLY EDITIONS, AND WHERE WE WANT TO BE
Abstract
Scholarly electronic editions up to 2003 have rarely extended beyond the model of print technology, either in terms of product (the materials included and the ways they are accessed) or process (the means by which they are made and by which they may be manipulated). However, some edition projects are beginning to explore the possibility of the electronic medium, and others may follow their lead as the basic tools for their making become more widely distributed. Yet this may only be a prelude to a much greater challenge: the making of what may be called fluid, co-operative and distributed editions. These editions will not be made or maintained by one person or by one group, but by a community of scholars and readers working together: they will be the work of many and the property of all. This approach will strain currently deployed data and organizational models, and will demand rethinking of some of the fundamental practices of the academy. However, the potential benefits to all involved, as readers, editors, commentators and critics engage together in the making and use of these, are considerable.
There has been around ten years of activity, sometimes frenetic, in the making of electronic scholarly editions.[1] One could mark the beginnings of this process by three events: the beginnings of the world wide web around 1992; the formulation of the Text Encoding Initiative (TEI) guidelines about the same period, culminating in the publication of the ›P3‹ version in 1994; and Jerome McGann's essay The rationale of hypertext which was drafted around this period.[2] Together, these provided three elements necessary for electronic scholarly editions: a cheap and efficient means of distribution; a set of encodings to underpin their making; and a theoretical imprimatur from a leading textual critic. Over the same period, the rise of digital imaging and the increasing holdings of images of primary textual materials in electronic libraries have added the possibility of large-scale inclusion of image materials in electronic editions. The effect of all these is that it is now probably impossible to find a single large-scale editorial project in western Europe or America which does not have already have, or is not actively preparing, a digital dimension.
There are, of course, many differences among the electronic scholarly editions which have so far appeared, and much discussion concerning their precise contents and emphases. Should they simply present images, or be centred around images, as in the model proposed by Kevin Kiernan?[3] If an edition includes many texts, should it include collations of all these; should it include also an edited text, and if so, how should this be constructed? Should it include commentary materials, and if so, what kinds of commentary and how should these be linked? Should we be making editions at all, with the implication that there is an editor whose opinions and interpretations might intrude, or should we satisfy ourselves with making archives, where an impersonal presentation might warrant readerly freedom? These discussions reflect debates which have been proceding in the editorial community for several decades now, and which now continue in the framework of the new medium.[4] Indeed, the continuation of these discussions in the electronic medium itself is a marker of the success of the new forms, as editors who up to ten years ago would not have considered using computers to make and distribute editions have adapted to the digital world, and translated their own methods and editorial theories to it.
Necessarily, much of the work of this first ten years has been experimental, and concerned with practicalities: what software, what hardware, exactly what encodings, should be used? Should these editions be distributed on CD-ROM, or on the internet? Recently, the rise of XML (Extensible Markup Language) and the development of a constellation of associated software tools have provided answers to many of these questions. The effect of all these is that we can declare that there are solutions to the immediate technical problems which vexed us in the last decade, of how electronic editions should be made and how they should be distributed. We may now make, with reasonable efficiency and at reasonable cost, editions of texts, from manuscripts and print editions, according to our own critical perspective. The expertise to do this is still too narrowly held, and we need more examples of good practice to guide those who are beginning this work, but this is coming.
Briefly, this is where we are now, and this is how we got to this point. We might assume that this is the end of the matter: that we have solved all the problems, that we have put in place a variety of comprehensive models, that all we have to do now until the end of time is choose our model and make our edition accordingly. Most emphatically, I do not think this is at all the case. The electronic scholarly editions we have been making so far do not represent any kind of endpoint. Indeed, I think they do not even amount to much of a beginning. In the rest of this paper I would like to sketch out why I think this, what kinds of scholarly edition we will find ourselves wishing to make in the next years, and what yet needs to be done to permit us to make these.
First, let us observe two things missing from almost all electronic scholarly editions made to this point. The first missing aspect is that up to now, almost without exception, no scholarly electronic edition has presented material which could not have been presented in book form, nor indeed presented this material in a manner significantly different from that which could have been managed in print. Many electronic scholarly editions present facsimile images. But print editions have included reproductions of manuscripts or other sources, in some form or other, for centuries. Some electronic editions present the images alongside transcripts; but print editions have long done this. Some electronic editions include commentaries and other editorial matter; there is hardly a print edition which has not done this. As for hypertext: even before print, scribes created manuscript pages which surrounded the text with all kinds of extra-textual material – commentaries, variant readings, indices, cross-references, glosses, pointers to every kind of matter.[5] Almost all we have done, in the first ten years of electronic scholarly editions, is find ways of mimicking on screen elements long present in print and manuscript. Indeed, in some respects electronic editions are actually a backwards step. Consider the presentation of variant texts. Traditionally, print editions showed variation in the form of a collation apparatus, showing at various points of a ›base text‹ the different readings of different witnesses. Instead of this, most electronic editions just show the different texts themselves, and leave it to the reader to discover where the variants are. Even where the variants are presented, they are usually presented in the same list form as they are in printed editions. Certainly, we can include much more in electronic editions, and certainly we can make it much easier to move between related points. But this hardly amounts to a revolution. At their best, so far, most electronic editions do the same as book editions: they just do more of it, perhaps with marginally more convenience. In essence, their product is not significantly different qualitatively to that of print editions.
The second missing aspect of most electronic scholarly editions relates to their failure to use new computer methodologies to explore the texts which they present: to be different in terms of process. The only tool many editions add is text searching – and many do not even provide that. Very often too computerized tools are not used in the preparation of the editions: a database might sometimes be used for gathering some data, but that is all. This is particularly surprising when one considers developments in other fields of knowledge. In the last decades, immense advances have been made in the sciences in the development of sophisticated methods for finding patterns in large quantities of disparate data. There are obvious opportunities for the application of such methods to data gathered by scholarly editors, on the agreements and differences at every level among the witnesses to a text. But very few scholarly edition projects have made any attempt to use these methods, and even fewer have attempted to make these available to others.
Clearly, the electronic edition of the future – that is, electronic editions which really exploit their medium, as fully as the best print editions since Aldus have exploited the printed page – must attend to these two fundamental deficiencies, of product and process. As to product: we can see that the electronic medium permits possibilities of dynamic interactivity which we have scarcely begun to explore. Some editions have already shown how the editor can provide different views on the one text, so that the reader can choose how to see a text: in a diplomatic transcription, in a normalized spelling and orthography; interlineated with variants from other texts, and so on. We can expect to see these models developed so that this is no longer an occasional feature, with some alternatives presented at some points, but becomes the fundamental guiding principle of the whole edition. That is: the reader can reshape the whole edition, from the very first view right through to every individual element. For example: an edition of a text in many versions would permit the reader to select the ›base text‹, or not have any base text at all; to select which different versions will be shown; to choose how each version appears, in what configuration of the version in its relation to other versions, and in what configuration of edited text against captured image. Some of this we have already seen, and we can expect more and more editions to take advantage of these facilities.
This extension of dynamic interactivity will change the relationship of the reader to the text he or she is reading. These will be ›lean-forward‹ editions, demanding our interaction.[6] This opens the way to these editions becoming closer to the immersive environments one finds in computer gaming. Indeed, the ideal reader of an ideal edition would behave much as does a computer game player: seeing puzzles in the materials presented, rearranging them to seek ways into the puzzle, trying out different solutions – what difference does it make if I read the text this way, with this variant – seeing the results, using what is learnt to frame yet further hypotheses, to create yet further readings. Neil Fraistat and Stephen Jones's MOOzymandias, and and Johanna Drucker's Ivanhoe Game are both experime_ntal moves in this direction. There are obvious pedagogical opportunities here.[7] For generations textual scholars have complained that nobody reads their editions. Through the imaginative use of this technology, scholarly editions could be taken from the rarefied world of the research library right into the classroom, right to the computer on the student's desk. This will require scholarly editors to think and work in unfamiliar ways, and will require many experiments, at least some of which will appear quite bizarre to those brought up on traditional norms of ›historisch-kritische Ausgabe‹ and its equivalents. At the least, this will blur the traditional sharp distinction between ›scholarly‹ editions and ›reader‹ editions, while the incorporation of textual scholarly matter in the kind of interactive pedagogical environments looked forward to by the experiments cited above will set different challenges. But the potential prizes are huge.
To achieve this, we will need to do more than add hypertext connectivity to existing models of the presentation of editorial data. We will need to find new means of visualization and presentation. Take the case of an edition of a work in many versions. Editors have traditionally used four means of visualizing the data:
1. Presenting text with apparatus of variants, with the apparatus usually presented in list form
2. Presenting texts in parallel, with or without some system of marking variant places
3. Presenting views of version relationships in some kind of tabular form: a ›stemma‹
4. Presenting images of the original witnesses, alongside forms of edited text
Even without moving beyond this four-fold frame, we can use the power of the computer just to present each of these four views more vividly, more accessibly, than is possible in print. Through these means, we might not only help scholars use scholarly editions but also make them accessible to a much wider range of readers. In what follows, I give examples from three editions in which I am currently involved, of Geoffrey Chaucer's The Miller's Tale; of the Greek New Testament being prepared by the Institute for New Testament Textual Research at Münster; of the Commedia of Dante Alighieri.[8]
For the first point, presenting text with apparatus of variants: in these three editions we are experimenting with having the variants at each word or phrase in any text ›float‹ above the word or phrase, and with having the variants appear in a separate panel as the mouse moves over the word. Thus, in our edition of the Miller's Tale: at line 73 of Link 1 in the Hengwrt manuscript, passing the mouse over the words ›eek and‹ shows this:
In the Münster Greek New Testament, we have the variants appear dynamically in a separate panel as the mouse moves over rather than in this pop-up. Naturally, in the Chaucer instance above one wants to know what the ›14 mss‹, ›28 mss‹ are, and also the different contexts in which this variant occurs. Clicking on the ›eek and‹ in the panel above has this information appear in another panel:

The top part of this view shows all the variants in this line stacked one above another: that is, there are no variants on the words ›So‹ and ›the Reve‹.
In a variant of this, we have the chosen base appear down a left column, with variants interspersed in a different colour, while lists of versions appear to the right. Here, we see this for the variants on line 10 of »Paradiso 1« in the Commedia:

This can be varied yet more by changing the base, or changing the selection of versions shown, and varied once more so as to show the original spelling of each word in each manuscript:

For the second visualisation, showing texts in parallel: we have developed means of showing any number of texts in lineated form, with the differences in each text coloured so that one can see exactly how and where they differ. Thus, for line 73 of Link 1 in the Chaucer:

As a variant of this, one can choose any two texts to be presented in parallel, once more with all variants marked. This view shows the comparison of lines 73-76 of the Hengwrt and Ellesmere manuscripts in Link 1:
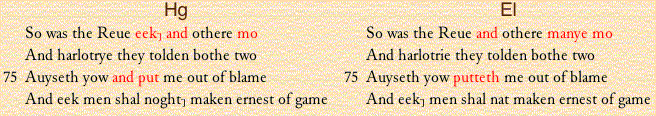
The selection of variants is under the editor's control, so that (as here) only those variants judged as significant may be shown. For the third visualisation, presenting views of relationships: we may present relationships more as growths, or networks, and less as rigidly directed trees. For the fourth visualisation, presenting images: it is a commonplace that high-quality digital images may give a far superior quality of reproduction than that normally available in print editions.
In print form, one cannot do more than present each of these visualisations separately, at best consecutively or adjacent, and leave it to the reader to trace the connections between the distinct views. There is potential to do much better in the electronic medium: to combine any of these visualisations, to help understand the many texts and their relations. We could link the first and fourth views to present image and text linked dynamically, so that when one moves the mouse over a word in the image, the transcription of that word appears above. Then, we could reverse this: move the mouse over a word in the transcription and the image of that word might appear. As a step beyond this: one could carry out a search on the text and have the ›hits‹ appear either as highlighted in the image, or the hits are extracted from the image (together with arbitrary context) and presented in tabular form, as a series of images. One could extend this by having variant texts at each word in the image appear over the image.[9] Similarly, one could present the second and fourth views simultaneously, so that parallel alternative texts could be presented in image form as well as in transcribed form.
In the Canterbury Tales Project we have been experimenting too with linking the first and third views also, so that the pattern of variants at any one point is mapped on the table of relationships we have deduced for the witnesses. Consider the readings at line 73 of Link 1 from The Miller's Tale again. It is difficult to make any sense of the bare statistics:
›and‹ 14 witnesses
›eek and‹ 28 witnesses
›and eek‹ 11 witnesses
›also and‹ 1 witnesses
Adding the details of just what are the 14 witnesses (actually ›Ad1 Ad3 El En3 Gg Ha4 Ha5 Ht Ii Nl Ox1 Ps Tc1 To1‹) hardly adds to clarity: it is just too much information. But when we relate the distribution of the variants among the manuscripts to the table of relationships we have deduced we see this:
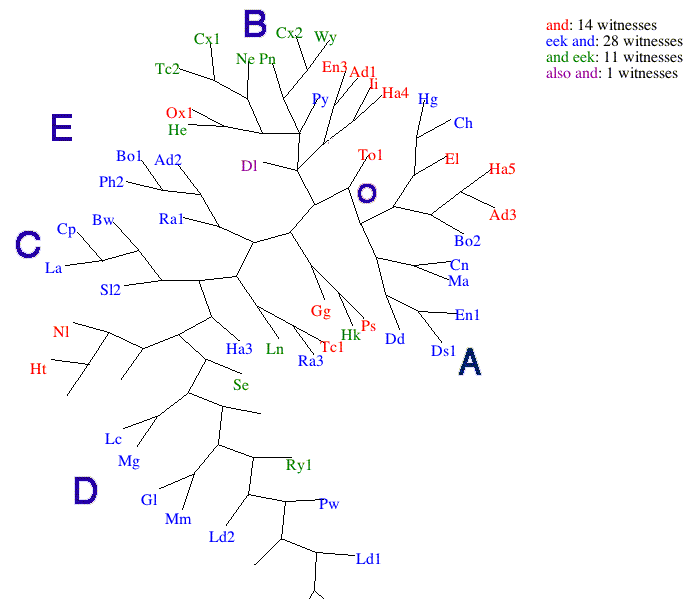
The large capital letters show the manuscript family groupings which we have determined with the help of evolutionary biology software. A glance at this table shows the dominance of the ›blue‹ reading, ›eek and‹: this is spread right across the whole tradition, and further is dominant in every group except the B group, which has ›and eek‹: a simple inversion. By contrast, the ›red‹ reading ›and‹ (the reading of the Ellesmere manuscript) is confined to a few of the O manuscripts (effectively, those nearest the presumed archetype) and a scattering of manuscripts elsewhere. It is notably not present in the three distinct groups A C and E. Traditionally, manuscript stemmata were abstract objects, leaving it to the reader to work out as best he or she might how it both explains and is explained by the patterns of variation at any one reading. Through this means we can make concrete the link between the variants at any one point and the overall pattern of variation in all the versions across the whole text.
These examples represent our experiments towards finding new ways to show the network of intricate relations which defines a text in many versions. Through these, we aim to make electronic editions which address the first deficiency I noted: they will represent a new kind of scholarly product, and not just a translation of print editions. Similarly, electronic editions may address the second deficiency I noted: they could utilize computer methods far more as process, both in the making of the edition by the editor and in its everyday use by the reader. So much of scholarly editing is a careful tabulation of the differences between texts (collation, that is); recording the differences, analyzing them both to understand and to explain; finding ways to present all this information. There is a compelling argument, that the great strength of the new medium is that this work can be made much more efficient and much more accurate by the use of computers.[10] New systems of data analysis might offer ways into all this material, and so permit us to see patterns and relationships always there, but never before accessible. In turn, we could use the explicatory power of the computer to allow readers to discover these, just as we do for ourselves. Thus, an editor need not just transcribe into electronic form, but can use computer programs to compare the transcriptions and create a full record of the agreements and disagreements among the witnesses. There are obvious analogies between this deduction of relationships from data of agreement and disagreement and the practice of evolutionary biology, where powerful computer programs have been developed over the last decades to hypothesize relationships between objects on the basis of the characteristics they share and do not share. Indeed, this is more than analogy: both textual traditions and living beings propagate by ›descent with modification‹, to use Darwin's concise phrase.[11] An editor can use methods to explore the tradition: to see the flow of readings across the many versions; to construct a hypothesis of the history of the text. Such hypotheses can have great explanatory power. The ›variant map‹ I cite above was made by exactly this procedure, and by this we are able in turn to help the reader ›see‹ just what is happening at any point in the text.
A well-made electronic scholarly edition will be built on encoding of great complexity and richness. As well as free text searching, efficient search systems can make use of this encoding to enable sophisticated searches, going considerably beyond the standard word and phrase searches. For example: in the three editions here discussed we know exactly what and how many manuscripts have each variant, and we know too what is present in other manuscripts at that variant. Therefore, we can find answers to questions such as ›show me all the variants present in manuscript X, in at least three of this group of manuscripts, and not in manuscript Y‹. Furthermore, one can provide the same tool to the readers, and link this to commentary on each reading, as we did for the General Prologue on CD-ROM and as we are doing for the Miller's Tale on CD-ROM.[12]
These are tools which might enhance our understanding of the many texts, and how they relate to one another, and which we might also use to help others understand them for themselves. But the vast quantities of digital information generated by digital photography and related technologies open up possibilities for whole new areas of analysis. We may have – indeed, we already do have – full digital image records of complete texts, even complete traditions, showing in full colour and in remarkable detail everything that can be seen on the page, and even things which can not ordinarily be seen on the page. There are many tools for digital pattern recognition (in every optical character reader package, for instance) and obvious opportunities (once more) for application of these to automated analysis of typeface and manuscript hands, analysis of print and manuscript page layout, analysis of decorative and bibliographic detail such as ornamentation and watermarks. Further, advanced mathematical analysis might find patterns in the data and so illuminate the physical processes attending the creation of print and manuscript book, and reveal the links between print and manuscript workshops, between compositor and compositor and scribe and scribe.[13] Here too computer visualization tools may make these discoveries accessible in dramatic new ways. For long, we have been used to seeing data in list form: lists of variants, lists of manuscripts: essentially, in a single linear dimension. Occasionally, tables of relationships might offer views in two dimensions, of graphs, networks, and trees. But computer displays can already offer us the illusion of a third dimension: imagine how we might see a single text, with the variants from other texts receding into the distance, or coming forward to the reader, with colours and shadings indicating yet further dimensions.
We may now make editions such as these: editions which present materials which can be dynamically reshaped and interrogated, which not only accumulate all the data and all the tools used by the editors but offer these to the readers, so that they might explore and remake, so that product and process intertwine to offer new ways of reading. A start has been made towards such editions (notably, the Canterbury Tales Project editions of the General Prologue and Miller’s Tale), but we have still much to learn about tuning the interfaces for the readers who may use them. The tools to make these editions are proven, and are now available to others.
While this may be revolution enough for some, I believe electronic editions in the next decades will undergo a still greater revolution than any I have already outlined, a revolution for which there are as yet no examples, and hardly any tools. So far, every electronic edition I know has had this fundamental similarity with the print editions of the last centuries: electronic editions, like print editions, are static objects. There is an act of closure, a publication. At that point the text, all text, all encoding, is frozen, either in the printed pages or in the computer files which compose the edition. Of course, electronic editions as I have been describing them permit an infinity of differing views and manipulations. But these are views onto and manipulations of unchanging data. Certainly, one can change the edition, by altering the underlying computer files and republish, over and over again. In practice, in many instances this does not happen at all: in paid-for publications in particular, electronic publication (like print publication) is usually a once-only affair, with few publications running to a second edition. Further, the cost of making even the smallest change may be disproportionate. Just to change one word, or even only one letter, might mean you have to remake the entire publication – again, as in print publication. Perhaps even more significantly: almost always, the only people who can make any such change are those responsible for the initial publication. Usually, too, the full text and encoding is just not available to anyone but the original makers. It is held in some ›back end‹, while the reader is given access only to an interface abstracted from this, and not to the full text itself. Even if you do have access to the full original text and its encoding: changing it, then republishing it all, are delicate operations, usually requiring considerable resources of knowledge, software and hardware.
So pervasive is this model that discussion of the long-term viability of these editions has centred on means of preserving these files. Indeed, in the UK an elaborate data infrastructure has been established, through the Arts and Humanities Data Service, exactly to ensure that the masses of computer files which are generated through scholarly projects have a long-term home.[14] Similarly, debate on how such files are to be made – what form they should have, how they should be encoded – has been dominated by questions of ›long-term archivability and interoperability‹.[15] An unfortunate result of this preoccupation is that sometimes it appears that projects are made more for archives than for users: that it is more important the data be in the ›right format‹ for the archive (usually, TEI encoded XML or SGML) than that the object be usable now. There is a winning simplicity about this model. These computer files are singular and discrete objects, just as books are. So, all we have to do is archive the files in some form of electronic repository, in the same way as we archive books in libraries, and we are done.
If we add to these electronic archives a publishing function – since the data will be in standard form, then it can all be published using standard tools – then we appear to have closed the circle. Thus, both STOA and the AHDS service providers permit varying forms of publication direct from their sites. In the last years, massive effort has gone into the making of electronic texts of all kinds. In the UK, many large scholarly projects have received considerable funding for making electronic scholarly materials, and the chief funder of this, the Arts and Humanities Research Board, has made it a condition of funding that these digital products must be deposited with the AHDS. We should expect then a flood of these into the AHDS, with many electronic texts being deposited with AHDS Literature, Languages and Linguistics.
But this is not what appears to be happening. Consider the AHDS Literature, Languages and Linguistics provider, hosted by the Oxford Text Archive (OTA). The OTA is the oldest electronic text centre for scholarly materials, founded in 1976 by Lou Burnard. It now has close to 2.500 electronic texts. One would expect that most of these would have been deposited in the last few years, as activity in making electronic texts has increased. Yet the reverse is the case. Texts deposited in the OTA are given a sequential identifier, and their dates of deposit recorded in the TEI header prefixed to each, so that one can calculate rates of deposit.[16] Text identifier number 1.758 in the Oxford Text Archive is the Aeneid, deposited in March 1993. That is: in the first seventeen years of the OTA, some 1.750 texts were deposited at a rate of around 100 a year. We are now (19 December 2003) up to identifier 2.469. That is: a further 711 texts have been deposited in ten years, a rate of 70 a year. It appears that the rate of deposit has actually fallen in the last ten years. Even more remarkable: not only has the rate fallen, but in the last years it has slowed almost to nothing. Text 2.453 is Fontes Anglosaxonici, deposited in September 2002: in fifteen months since then, only sixteen texts have been deposited.
Why is this? A well-resourced and well-run archive has been established, just to receive electronic scholarly texts; a huge number of such texts are being made; but the scholars who make them are not putting them in the archive. Of course, we can see why: many texts (most of the texts in the OTA, in fact) were deposited before the web arrived. As the web has matured, and as the tools for publishing on the web (and in CD-ROM) have improved, these texts are appearing on the web. This is indeed perfectly reasonable. If you can publish on the web where anyone can find and use your text, why deposit in an archive?
This suggests that there is something deficient in the model, of making single discrete computer files whose content is frozen and then deposited in archives. An alternative model is that of the ›digital library‹: these files are accumulated into large digital collections and published together on the web (perhaps with pay-for access). This solves a key difficulty with the archive model: archives typically provide the data but no tools; digital libraries may offer display and search tools for the data. But, the plethora of digital libraries appearing on the web in many different forms has created a new difficulty: each comes with its own encoding, its own tools, its own conventions. Obviously, we want to draw materials from different digital libraries: to combine this material from that digital library with that from this digital library. Hence, the massive current interest in ›interoperability‹ (a Google search for this word on 19 December 2003 turned up over a million hits; searching for ›interoperability digital libraries‹ gave 75.000 hits). Yet really, all we are doing with digital libraries is replicating, on a yet larger scale and in yet more fixed form, the notion of the scholarly object as a closed entity: we may pile it together with other like and unlike objects, we may display it in various ways, we may retrieve it, (hence, the emphasis in ›interoperability‹ studies on search strategies), but in a digital library the object itself is even further from the individual reader.
Why does this matter? Consider what a scholar, or any reader, might want to do with an electronic text: for example, with the electronic edition of the Commedia of Dante Alighieri we are making. We are providing transcripts and collations of seven manuscripts and two modern editions, with many tools for searching and viewing these. But we are not providing any commentary or any translation. A reader might want to attach commentary, annotations, or translations to any point of our edition, or indeed throughout. There are many more manuscripts, many more editions: a reader might wish to import these whole into our edition, with all links functioning so that there is no distinction of interface, and all tools work for the new as for the old. We do not, ourselves, offer our own edited text. But the reader may wish to make his or her own edited text, perhaps by taking over an existing edition and substituting his or her own readings at various points. Further, although we have put massive effort into our transcripts and collations, there will be errors within them. It should be possible for the reader to correct these, or supply new readings, but yet to have all the commentaries and translations attached to these points still function (or, if they are rendered out of date, fail gracefully). The reader may want to do much more than just alter text here and there, too. The Commedia contains hundreds of names, of people and places. An obvious task is to encode all these, to enable all kinds of data analysis and linking (with, for example, external exegetical materials). We have done none of this, but a reader may well want to do it, and then build his own work on top of it.
In effect, this model suggests that I, as a reader, want to make ›your‹ edition ›my‹ edition; and that I, as an editor, want you to make ›my‹ edition ›your‹ edition. Further: suppose I put all this effort into making ›my‹ edition from ›your‹ edition: correcting many readings, adding whole new layers of encoding, linking commentaries and translations. Then, I may want to publish this. The next reader might then want the choice to strip out all or some of my augmentations, then may choose to add his or her own materials on top of all or some of mine, and then wish to publish this too.
This view of what editions might be some time in the future opens up many possibilities. A school-teacher wants to build a lesson about a scene from Hamlet: in a few minutes, he or she could combine different versions of key lines of the text, linked with images of those lines in the Folio and Quarto prints, commentaries, images of performances. The students could take this, and add more to it for themselves, so that each creates a unique window on this part of Hamlet. A scholar preparing a scholarly article similarly could not only attach links to the edition, but could attach his or her own links from the edition to sections of the finished article, which others could follow as they choose.
There appear to me to be huge benefits in this approach. Scholarly editing has for centuries distinguished between editors and readers: we, the editors, are gifted with special access to the materials, and we are licensed by the academy to make editions which you, the readers, accept. This approach attacks this distinction. All readers may become editors too, and all editors are readers before they are editors. This does not propose that all readers should become editors all the time: most of us will be content to accept, most of the time, what Gabler tells us about Ulysses, or Werner tells us about Dickinson. But any good reader must sometimes be an editor. Gaps may also appear in other barriers, long present within the academy: that between ›documentary‹ and ›critical‹ editing, that between textual scholarship and literary scholarship. We are all engaged in the business of understanding: distributed editions fashioned collaboratively may become the ground of our mutual enterprise.
Another benefit is that this offers the best solution to the question of the long-term usability of editions. The best guarantee that an electronic edition should remain usable is that it should be used. A computer file deposited in an archive where its survival depends entirely on the internal routines of the archive is vulnerable. One break in those routines and the file could go the way of the thirteenth century in the 1975 film Rollerball (where all history has been put on a computer which one of the characters visits in search of information about the thirteenth century, only to discover that due to a computer fault ›We have just lost the entire thirteenth century‹).[17] We could put our work on the Canterbury Tales into the Oxford Text Archive, and it would last as long as the archive, which itself will last slightly longer than its public funding. Or, we could put it on the internet in a manner that allows it to be appropriated by others, augmented, corrected, infinitely reshaped. In the first form, in the archive, it would stay exactly as I left it, but rather few people would use it. In the second, after a few years we might hardly recognize our creation – but many would have used it, and the more people who have used it the more it will have changed.
The brief history of computing so far is that if something is worth doing, and it can be done, then it will be done, no matter how difficult the task. The success of optical character reading techniques, or digital imaging manipulation software, testifies to this. What I describe here appears worth doing and there is nothing theoretically impossible in this vision. We are dealing only with the manipulation of known data. But it will be difficult, perhaps horrendously so. One thing alone: presently, almost all the textual data on which one would build such co-operative texts is encoded in XML. XML notoriously supports but one hierarchy per document. This was always a bad idea in the humanities, but we have learnt ways of living with it, in our hermetic world of separate documents, each with its own hierarchy and with its own set of workarounds.[18] But for this vision to work, we will have to overlay document on document: to infiltrate new encodings from one document into another so that they cut across the fixed hierarchy fixed within it (for example: encoding a metaphor which runs across line and paragraph divisions). We will have to work out methods of inheritance to cope with situations where editor A attaches commentary to line x; editor B changes a word in line x, or removes it entirely: what happens to the commentary? We will have to work out procedures for labelling exactly who did what to the text and when, and we will have to fold in capacities for reversion: to return to previous versions, to see the text as made by a particular editor at a particular moment.
Above all, we will have to work co-operatively, with all this implies for academic practice, for publication and accreditation strategies, and for copyright and authority controls.[19] Who authorizes changes? What parts of the edition are held where; who ›owns‹ what? Existing electronic editions, like print editions, are discrete collections of data, which can be physically located in a single place: on a single disc or server. These fluid and co-operative editions will be distributed: every reader may have a different text, and for any screen the text may come from many different places – a manuscript transcription from one site, a layer of commentary from one scholar, textual notes and emendations form another, all on different servers around the globe. In a sentence: these will be fluid, co-operative and distributed editions, the work of many, the property of all.
None of this will be easy, and no scholarly edition like this yet exists. The nearest analogy may be the Romantic Circles website, but this does not permit the kinds of collaborative revision of the contents here envisaged – rather, it is a collection of many parts, each separately owned.[20] However, there are already systems in place which do some of what I here describe. Content management systems permit cooperative work, albeit (usually) within closely defined communities. Version control systems exist offering reversion capacities such as those I here outline, though I know of none that permit filtering at the level of the individual markup event. Of course, we do have many search systems, but I know of none that will combine text and markup from separate documents and search on the combination, with each search refashioning itself as the markup and text changes. There is much to do. As yet, we are not even agreed what path to follow towards this goal: should we try to create a single architecture, which all must use? Or, should we fashion something like a tool set, an infrastructure which may be used to make what editions we please? Or do we need something yet more anarchic: what Michael Sperberg-McQueen describes as a ›coral reef of cooperating programs‹, where scattered individuals and projects working ›in a chaotic environment of experimentation and communication‹ yet manage to produce materials which work seamlessly together. Unlikely as it sounds, and untidy as it may seem to those used to ordered programs of software and data development, with the neat schedules of work-packages so admired by grant agencies, this last may be our best hope. This model has certainly worked in the software world, where open source software developed in the last years under these conditions drives large sections of the community.[21]
Will this, then, be the end of our quest? Sometimes it seems that we are explorers moving towards an ever-receding horizon. In the mid-80s we thought that what we needed was a scheme for encoding, and systems for digital capture both of text and images. By the mid-90s we had those, and we then began to think that we needed better interfaces and better tools. Now, we have those, and now I think we need to be able to make fluid, co-operative and distributed editions. When we have those, perhaps we will need something more – perhaps there will always be something more.
Dr. Peter Robinson
De Montfort University
Centre for Technology and the Arts
Room 1.01, 1st Floor
Clephan Building
The Gateway
Leicester LE1 9BH
United Kingdom
peter.robinson@dmu.ac.uk