HNML - HYPERNIETZSCHE MARKUP LANGUAGE
Abstract
The technical and organisational structure of HyperNietzsche developed in such a way that creating an appropriate markup language proved necessary. Derived from the established standard TEI P4, it enables the Munich Nietzsche Team to encode transcriptions of Nietzsche manuscripts, new editions of Nietzsche works, and essays submitted by Nietzsche scholars. Its main characteristics are: extensibility, mainly realized by avoiding the storage of textual data in attributes; a strong distinction between the description of manuscript features and editorial interventions and comments; an easily applicable facility for linking a document to related documents.
A short survey of the tasks of the Munich HyperNietzsche Team[1] will help describe the situation, from which the need for a new markup language resulted. The text corpus envisioned in the current phase of HyperNietzsche is the Philosophy of the Free Spirit (Philosophie des Freigeists), which covers the following works: Menschliches, Allzumenschliches (1879), including the later additions Vermischte Meinungen und Sprüche (1879) and Der Wanderer und sein Schatten (1880); furthermore Morgenröthe (1881) and Die fröhliche Wissenschaft (1882) – and all the corresponding ›Vorstufen‹ (preliminary stages) in the extant manuscripts.
1) Digitization in colour and in high resolution of around 30.000 pages of primary sources: manuscripts, letters, first editions, photos and other biographical documents: for example receipts for book purchases. However, HyperNietzsche had to cope with some legal issues first. Unlike most philological/humanist projects, the HyperNietzsche project also employs jurists. An agreement between the Stiftung Weimarer Klassik and the Association HyperNietzsche had to be made up before the mass digitalisation and publishing could begin. The most important point is that the Association HyperNietzsche is permitted to publish the digitized material freely on the internet for research purposes.
2) Digital classification, retouching and publication of around 6.000 facsimiles of original Nietzsche manuscripts: This represents the complete genetic dossier of Der Wanderer und sein Schatten and Morgenröthe, beginning with the note books, going on to fair copy and printers copy, and finally to the first edition. Once published, the digital facsimiles constitute an ›open source‹ for any kind of further transformation, for example a printed facsimile edition of Nietzsche manuscripts. Within the digital medium, facsimile editions are already available, of course.
3) HNML-encoded transcription of 3.000 manuscript notes, of which around 1.000 have already been published in HyperNietzsche.
4) New editions of ten of Nietzsche's works are in progress. The new edition of Der Wanderer und sein Schatten will be published in April 2004, as part of version 0.5 of HyperNietzsche.
Additionally, the Munich Team did editorial work on some philosophical and/or philological essays which were published in HyperNietzsche. Within this area, legal aspects are also of major importance: The rights of the author have to be preserved, and at the same time, free access within the frame of scientific use has to be granted. The OpenKnowledge license, which has been made up for HyperNietzsche, in principle works as follows: Every user who downloads data (i.e. a contribution by a HyperNietzsche author) from HyperNietzsche, implicitly accepts the OpenKnowledge license. Within ten years after the download, he has the right to copy and distribute the work on any data carrier, as long as he uses it for scholarly/scientific purposes. The user, too, may allow others to copy and disseminate the data for scientific purposes. For all other cases, especially the commercial use of his works, the author keeps the right to permit or prohibit further copying and dissemination. In those cases, the Association HyperNietzsche is not involved.
For contributions to be published in HyperNietzsche, there is a choice of data formats, which are all open and freely accessible: PDF, HTML, JPEG, and, basically, any XML-based format, like HNML.
HNML – HyperNietzsche Markup Language – is an XML format designed by the Munich Nietzsche Team in order to fill the gap between the relational organisation of documents, which is realized by our database, and the need for encoding the structure of the documents.
HNML is derived from TEI-XML. Initially, we planned to apply the TEI P4[2] guidelines. However, we soon faced the problem that the possibilities of encoding manuscripts provided by TEI P4 did not meet all our requirements. Deviations from the TEI guidelines were inevitable, but nevertheless, we decided to remain as close to the TEI elements and structure as feasible. One feature of HNML is its ›scalability‹ regarding the depth of structure within a document: as one doesn't know how complicated Nietzsche's manuscripts can get, until one has analyzed – if not encoded – them all, the encoding scheme must provide enough extensibility.
As one basic consequence, the storage of manuscript data in attributes of XML elements had to be avoided, because one may face the need for inserting additional meta-information to such data,[3] which is not possible with attributes. Thus, HNML contains more elements and less attributes, and no HNML attribute contains manuscript data. Another reason for designing a new markup language was the fact that there were no tagsets available for some manuscript features, like the overwriting of one letter by another. Moreover, HNML makes a sharp distinction between the description of manuscript features and any correction and comment by the editor.
However, as standardization is important for interchangeability, we will provide a TEI version of all our HNML documents. Of course, there will be loss of information for the time being, as not every HNML tag/tagset can be translated into TEI P4, but as the TEI guidelines are in constant development, this problem might be solved in the future.
Initially designed for encoding manuscripts, we soon extended the scope of HNML: we also use it for encoding our new editions of Nietzsche's works and for publishing essays.
As a matter of fact, every HNML-encoding of Nietzsche's manuscript writing generates at least two transcriptions: a ›diplomatic transcription‹ and a ›serialized transcription‹ (both in HTML format) are generated from the HNML document on request by the user.[4] The third kind of transcription, the ›ultra-diplomatic transcription‹, requires some human intervention, as it represents very detailed physical features in an ›iconic‹ way, which can hardly be encoded by markup and displayed in HTML: the exact positioning of words, passages and graphics on the paper, the exact font size and the like. Finally, there is a fourth kind of transcription. The ›interactive transcription‹ provides the user with a click-sensitive digital facsimile of a manuscript page: when the user clicks on a word, its transcription becomes visible.
The descriptive features of HNML for transcriptions can be grouped into the following subsets:
1. writing hand: Nietzsche, Peter Gast or unknown; handwriting: German, Latin, Greek; writing implement: pencils and ink in various colours;
2. spatial order and interrelations of words or phrases: page breaks; paragraphs; line breaks and hyphenation;
3. revisions, markup and instructions by the author/writer: additions; deletions; overwriting; underlining; repetition of words in order to assemble spatially diverse portions of text;
4. writing layers or levels: grouping of acts of revision which constitute one stage of the writing process;
5. editorial interventions, and optional comments by the transcriber: these are needed for the serialised transcription, which is a corrected rendition of the manuscript text in its final state;
6. unreadable or unresolved letters, words or phrases;
7. special characters which are represented by empty elements to facilitate the processing.
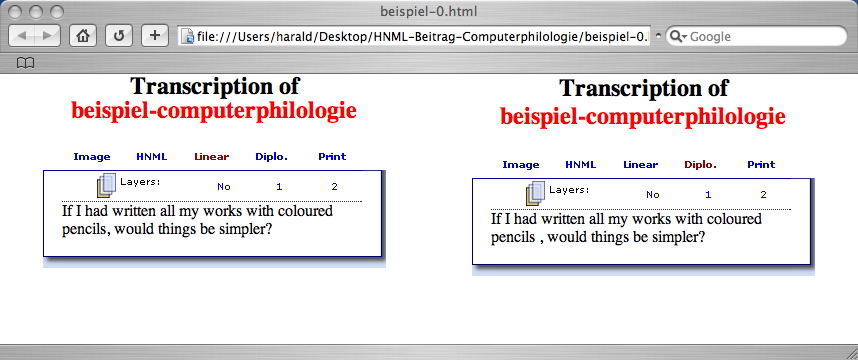
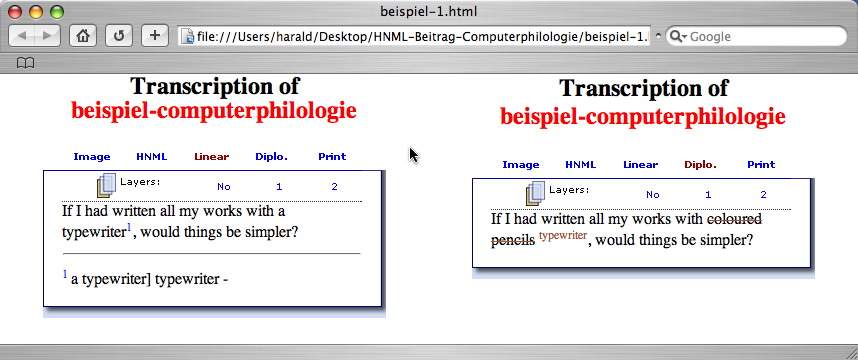
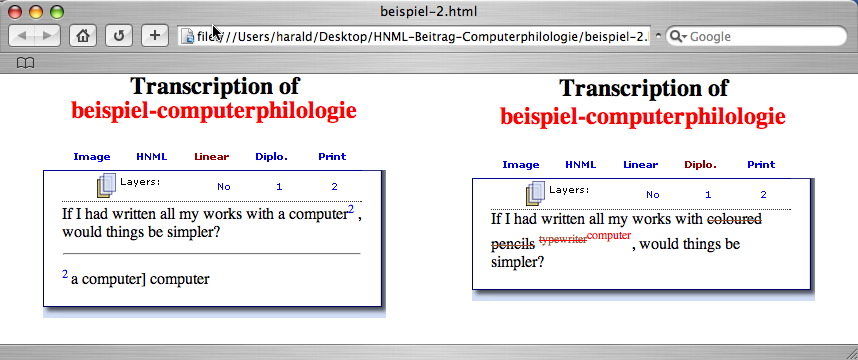
Feature no. 4 is a very recent development. The idea is to give a grouped order of the actions described in the third group (revisions, markup and instructions) – and, as a consequence, in the fifth group (editorial interventions): for every writing layer, there will be a diplomatic transcription as well as a serialized transcription. Of course, a distinction of writing layers is only possible in some of Nietzsche's notes. Additionally, it implies much more interpretation, and therefore subjectivity, than all the other encoded features. The result tends towards a genetic edition. However, the user can always decide whether the writing layers are displayed or not. If not, only the results of all writing processes, i.e. the physical appearance of the manuscript is presented. On the technical side, the encoding of writing layers by HNML is quite simple. The information about the writing layer is stored in an attribute within the element that describes the action of revision itself. For example, an addition which took place in writing layer 1 would be encoded like this: <add lay="1">ADDED_TEXT</add>.
The possibilities of representing a two-dimensional object and additional non-spatial information by means of a two-dimensional display are limited: the writing layers (which are of temporal nature) have to share the means of representation with the spatial information. Consequently, a conventional schematization is necessary, and the visualization becomes somewhat hybrid. For example, we use superscript (and a smaller font) to indicate an interlinear addition, which only resembles the physical appearance in the manuscript, but cannot imitate it. A phrase printed in superscript takes all the horizontal space, as if it was not printed in superscript. Additions that belong to different writing layers are displayed in a cascading way: with every new writing layer that has been entered, the superscript appears a little higher, so the nesting of the different layers becomes quite obvious. The following example shows how writing layers are encoded and displayed:
<N>
If I had written all my works with <sepia><str lay="1"><black>coloured pencils </black></str></sepia><editor lay="1"><sic><red><str lay="2"><add lay="1"><sepia>typewriter</sepia></add></str></red></sic><corr>a typewriter</corr><enote></enote></editor><editor lay="2"><sic><add lay="2"><red>computer</red></add></sic><corr>a computer</corr></editor>, would things be simpler?
</N>
In the first screenshot, only the basic writing layer (= layer 0) is presented; there are no alterations yet. In the second and third screenshot, the layers 1 and 2 are selected.
HNML also turned out to be useful for the new editions of Nietzsche works which will be provided by the Munich Team. Identical or similar tags are used with transcriptions, works, and essays. There are the following groups of features:
1. spatial order: page breaks; paragraphs; line breaks and hyphenation;
2. markup (highlighting) by the author;
3. editorial interventions by the editor;
4. special characters which are represented by empty elements to facilitate the processing;
5. footnotes by the author.
Every editorial intervention is made transparent to the reader by a critical apparatus. In the apparatus, the corresponding reading of every extant ›Vorstufe‹, i.e. note in a manuscript that is a predecessor of the work text, is given. The following tagset was designed for the encoding of editorial interventions/apparatus:
<editor>(The number of <rdg> tags within one editor tagset varies from 2 to 5, depending on how many manuscripts are extant).
There are two text formats that can be used for the publication of essays: HTML and XML (that is, any XML-based document format). For those essays which are edited by the Munich Team, HNML is used. Besides, every contributor is encouraged to encode his/her essay in HNML, too; a specially configured XML editor[5] will be freely available soon. By the use of HNML, it is assured that the formatting of the essays is uniform, and that there is a logical/structural markup that may be used for information retrieval. For example, the paragraphs of an essay are numbered automatically, thereby providing a granularity for referencing and processing which should be quite appropriate for digital documents: the division by page breaks mostly used in paper documents has the disadvantage of not corresponding to the logical structure of a document. But the most important feature of HNML regarding essays surely is its support of dynamic contextualization.
The basic elements of the HyperNietzsche infrastructure are signatures; if an object has a siglum, it exists in the eyes of HyperNietzsche, and can be referred to and processed. The dynamic contextualization uses the signatures by gathering everything (document, or, in Pearl Diver Model terminology: ›pearl‹, see Michele Barbera/Riccardo Giomi The Pearl-Diver Model. The HyperNietzsche Data Model and its Caching System in this volume[6]) that contains a certain siglum. There are three HNML tags, which refer to three categories of HyperNietzsche entities: authors, contributions, material. For example, if an essay cites a certain note in a notebook: N IV 4,23[2] (note no. 2 on page 23 of notebook N IV 4), a link to all the other contributions relating to that note is generated. An HNML example: »Nietzsche wrote down in simplification of Epicur on <material sig="N-IV-4,23[2]">page 23 of N IV 4</material> that metaphysics were of no use.« Obviously, the task of the tag is to connect the author's arbitrary way of citing, which is addressed to the reader, to the canonical signature, which is adressed to the system.
The contextualization tags are available in all three types of HNML-encoded contributions: transcriptions, text editions, and essays. But also HTML-encoded contributions, like commentaries or reviews (for which there are currently no HNML schemes available) may contain contextualization tags, as there are HTML versions of these tags, too.
Dr. Harald Saller
Projekt HyperNietzsche
Ludwig-Maximilians-Universität München
Schellingstr. 9
80700 München
haraldsaller@onlinehome.de