Abstract
This paper describes plans for a diachronic corpus of German, which contains texts from Old High German to Modern German. In order to serve as a resource for research questions from many different fields (linguistics, literature, lexicography et cetera) the corpus must have a flexible architecture as well as a high degree of standardization of content. This flexibility is possible through a multi-layer standoff corpus model where the texts are stored in a central database. Standardization is ensured through common tagsets on each annotation level.
Der vorliegende Aufsatz hat die Konzeption eines diachronen Korpus des Deutschen zum Gegenstand. Dieses Korpus soll Texte von den althochdeutschen und altsächsischen Anfängen der Überlieferung bis – in sinnvoller Auswahl – hin zum älteren Neuhochdeutsch (bis um 1900) enthalten. Zu entwickeln ist es im entstehenden Projekt DeutschDiachronDigital (DDD), einer bundesweiten Initiative von Forscherinnen und Forschern aus der (historischen) Philologie, der (historischen) Sprachwissenschaft sowie aus Literaturwissenschaft, Korpuslinguistik und Informatik. [1]
In diesem Beitrag beschreiben wir allgemein die Vision eines standardisierten diachronen Korpus des Deutschen, das für möglichst viele Nutzungsinteressen offen bleibt, und gehen dabei ganz speziell auf die bisher für das DDD-Projekt getroffenen Entscheidungen ein. Ausführlicher wird schließlich dargestellt, nach welchem Ablauf eine Quelle entsprechend den DDD-Maßgaben aufgearbeitet werden soll.
Die Erstellung von historischen und diachronen Korpora ist sehr ressourcenintensiv und teuer. Das bedeutet, dass ein solches Korpus für möglichst viele unterschiedliche Interessen nutzbar sein muss.
Wir listen hier exemplarisch ein paar mögliche paläographische/typographische, lexikographische, sprachgeschichtliche, sprachwissenschaftliche, text- oder literaturwissenschaftliche Fragetypen, die an ein historisches und/oder diachrones Korpus herangetragen werden könnten, auf.
Ein Korpus als Textsammlung hat dabei gegenüber einer elektronisch vorliegenden Edition eines Textes den Zweck, dass die Texte miteinander vergleichbar sind. Das gilt sowohl innerhalb einer Sprachstufe als über Sprachstufen hinweg. Mit einem Korpus muss man qualitative genauso wie quantitative (statistische) Fragen beantworten können.
Synchrone qualitative Fragestellungen könnten zum Beispiel sein:
Gehen Buchstabenligierungen in Handschriften des Typs xy gemeinhin über Kompositionsfugen oder über die Fugen zwischen logischen Wortformen innerhalb zusammengeschriebener Textwortkomplexe hinweg?
Wo weichen die Ausgänge kongruierender Adjektiv-Substantiv-Syntagmen in frühen althochdeutschen Texten ausdrucksseitig voneinander ab, wo hingegen sind sie homonym? Gibt es darunter heterographe mutmaßliche Homophone?
Synchrone qualitativ-quantitative Fragestellungen sind:
Welche Schreibvarianten und welchen Wortschatzreichtum (Type-Token-Verhältnis) bietet der Text xy im Vergleich zu seiner Parallelfassung qz ?
Welche Paradigmastellenbelegungen von Vollverb-Stämmen kommen in einem mittelniederdeutschen Text der Textsorte xy wie oft vor?
In welchen strukturellen Merkmalen unterscheiden sich Textmengen aus Gedichten von solchen aus Prosatexten im Mittelhochdeutschen?
In welchen Texten kommen Spielarten des Ortsnamens xy und des Personennamens qz zugleich vor?
Lassen sich Wortschatzcharakteristika in der Romansprache mit weiblicher versus männlicher Urheberschaft festmachen?
Vorwiegend diachrone oder sprachvergleichende qualitative Fragestellungen könnten sein:
Wie entwickelt sich die Schreibung der Wortformen zum ›Ecke‹ bezeichnenden Hyperlemma über die hochdeutschen Sprachstufen hinweg?
Welche Entsprechungen hat das lat. Lemma pulcher in althochdeutschen Übersetzungstexten, wenn die Adjektivform Personen charakterisiert?
Diachrone qualitativ-quantitative Fragestellungen könnten sein:
Wie stellt sich die Finitverb-Stellung in Hauptsätzen mit analytischen Prädikatformen altsächsisch versus altbairisch statistisch dar?
Wie lang sind untergeordnete Teilsätze in altdeutschen autochthonen Texten gegenüber Übersetzungstexten?
Nimmt die variatio sermonis vom Mittelhochdeutschen zum Frühneuhochdeutschen in geistlichen Texten zu?
Diese exemplarische Auswahl von Fragestellungen zeigt bereits, welche Eigenschaften ein diachrones Korpus haben muss: Es muss vergleichbare Texte aus verschiedenen Sprachstufen / Genres und so weiter enthalten, man muss einzelne Teilkorpora auswählen können, und die Texte müssen mit Meta-Informationen annotiert sein.
Obwohl bereits viele historische Texte elektronisch vorliegen[2], können bisher kaum systematische Untersuchungen über verschiedene Texte einer Sprachstufe oder über Sprachstufen hinweg durchgeführt werden: die Digital-Texte sind nicht miteinander vergleichbar, da sie sich in Diplomatizität, Feinkörnigkeit der bibliographischen Angaben und anderen Annotationen unterscheiden; außerdem sind die verschiedenen Sprachstufen des Deutschen unterschiedlich gut abgedeckt. Eine Hauptaufgabe von DDD ist es also, aus vielen unterschiedlichen Einzeltexten ein Korpus zu erstellen. Ein solches historisches Korpus muss einerseits eine möglichst flexible Architektur haben, damit jederzeit neue Texte und Annotationsebenen aufgenommen werden können und andererseits inhaltlich vieles standardisieren, damit vergleichende Untersuchungen möglich werden.
Beide Aspekte werden in den nächsten Abschnitten genauer dargestellt. Das Projekt ist stark interdisziplinär: in unserer Korpusarchitektur sind wir vor allem durch zwei Forschungsbereiche beeinflusst: die elektronische philologische Textverarbeitung (Computerphilologie, ›Humanistic Text Processing‹) und die Korpuslinguistik (Computerlinguistik, ‹Natural Language Processing›).[3]
In der Philologie sind in den letzten Jahrzehnten Methoden für die Volltextdigitalisierung (Retrodigitalisierung[5]) entwickelt worden, um Digital-Ausgaben zu erstellen. Gute Digital-Ausgaben sind keine reine Digitalisierung einer Textfassung, sondern verbinden sehr detailliert verschiedene Textfassungen miteinander und mit einem kritischen Apparat und manchmal mit weiteren Ressourcen, zum Beispiel mit Wörterbüchern (wie im Projekt Mittelhochdeutsches Wörterbuch[6]) oder mit einer Stemma-Berechnung[7]; in vielen Fällen sind Digital-Ausgaben seitenweise mit Digital-Faksimiles aligniert. Allgemein enthalten solche Digital-Editionen viel Wissen über einen einzelnen Text, aber wegen der fehlenden Standardisierung gibt es, wie bereits dargestellt, oft keine Vergleichsmöglichkeiten zwischen den Texten; diachrone Studien sind nur schwer möglich.
In einem Korpus kann nicht jeder Text die gleiche sorgfältige philologische Behandlung erfahren, wie es in Einzel-Editionen möglich ist. Trotzdem übernehmen wir aus der Computerphilologie hohe Ansprüche an die Diplomatizität (Urkundentreue), ferner die Möglichkeiten, zu einem Text weitere Informationen hinzuzufügen, etwa Digital-Faksimiles zu alignieren.
Während sich die philologische Textverarbeitung zumeist auf die sehr detaillierte Erfassung und Beschreibung einzelner Texte (oder Werke eines bestimmten Autors) bezieht, beschäftigt sich die Korpuslinguistik mit Textsammlungen[8]. Dabei liegt der Schwerpunkt eindeutig auf der (automatischen) Verarbeitung großer Textmengen aus modernen Sprachstufen[9] – auch wenn natürlich historische Korpora und andere sogenannte ›special corpora‹ (im Sinne von Sinclair; siehe unten) bestehen[10]. Es gibt viele Definitionen von ›Korpus‹, wir beziehen uns hier auf eine relativ eng gefasste von John Sinclair:
A corpus is a collection of pieces of language that are selected according to explicit linguistic criteria in order to be used as a sample of the language [...] A computer corpus is a corpus which is encoded in a standardised and homogeneous way for open-ended retrieval tasks. Its constituent pieces of language are documented as to their origin and provenance. [11]
Aus dem Zitat wird deutlich, wie sich Korpora von Digital-Ausgaben unterscheiden: Ein Korpus besteht aus mehreren Texten, die nach vorgegebenen Kriterien ausgewählt, und – im Gegensatz zur Digital-Ausgabe – standardisiert und mit weiteren Angaben versehen (annotiert) sind. Bevor wir im Folgenden die einzelnen Bereiche Korpuszusammensetzung, Annotation und Auswertung in DDD genauer besprechen, möchten wir kurz einige Eigenschaften großer Korpora beschreiben und zeigen, welche wir übernehmen.
Bisher sind die meisten Korpora in einer flachen Datei gespeichert, in der alle Annotationen an einzelnen Wörtern (Tokens) hängen. Jede Annotationsebene (also etwa Lemma oder Wortart; siehe nächsten Abschnitt) ist durchgängig für das ganze Korpus annotiert. Bei großen Korpora moderner Sprachstufen erfolgt die Annotation automatisch, wobei eine gewisse Fehlerrate in Kauf genommen wird. Für DDD wäre eine solche flache Dateistruktur nicht passend: es muss möglich sein, jederzeit Annotationsebenen hinzuzufügen, ohne dabei die bestehenden Ebenen zu stören; und es muss möglich sein, ausgewählte Teile eines Korpus mit zusätzlichen Annotationsebenen zu versehen. In den letzten Jahren sind mit den sogenannten Stand-off-Korpora passendere Korpusmodelle entwickelt worden.[12] In Stand-off-Korpora werden die Daten in einer Referenzdatei (Timeline) gespeichert; die Annotationsebenen sind dann getrennte Dateien, die jeweils auf bestimmte Stellen in der Referenzdatei verweisen.
Die Zusammensetzung eines Korpus bestimmt, wofür das Korpus eingesetzt werden kann. Da das DDD-Korpus für viele unterschiedliche Forschungsfragen genutzt werden soll, muss die Zusammensetzung möglichst ›repräsentativ‹ sein[13]. Außerdem muss die Möglichkeit offen bleiben, jederzeit weitere Texte hinzuzufügen.
Für vergleichende Untersuchungen – seien dies Untersuchungen zum Sprachwandel, Genrevergleiche oder auch lexikographische Untersuchungen – ist eine Vergleichbarkeit über verschiedene Sprachstufen hinweg nötig; im Idealfall sollte sich also nur ein einziger Parameter (zum Beispiel: Zeit) unterscheiden, während alle anderen Parameter (wie Textsorte, Formalisierungsgrad) gleichbleiben. Das ist natürlich bei älteren Sprachstufen schwerer möglich als bei heutigen: Zum einen, weil sich viele Textsorten (wie Roman oder Tageszeitungsberichte) erst später entwickelt haben und andere (wie Evangelienharmonien) verschwunden sind, und zum anderen, weil viel weniger Material erhalten ist. Man erzielt also immer nur in Teilbereichen Kontinuität. Wenn man eine Matrix aller relevanten Parameter aufstellt (beispielsweise Sprachstufe, Textsorte und Dialekt), bleiben besonders bei historischen Korpora zwangsläufig einige Zellen leer[14].
In DDD werden die Texte nach den Parametern Zeit, Dialekt und Textsorte ausgewählt. Die daraus entstehende Matrix ist allerdings nur für die Sprachstufen Mittelhochdeutsch und Frühneuhochdeutsch wirklich anwendbar. Davor gibt es zu wenige Texte, daher werden alle größeren althochdeutschen und altsächsischen Texte aufgenommen. Danach gibt es zu viele Texte, daher beschränken wir uns im älteren Neuhochdeutschen zunächst auf die drei hochsprachlichen Textsorten Roman, Zeitung und Brief.
In Sinclairs Definition oben ist von »pieces of language« die Rede, nicht von ›Texten‹. In manchen Korpora werden bewusst statt ganzer Texte nur Textausschnitte einer gewissen Länge aufgenommen, damit diese direkt miteinander verglichen werden können. DDD hat dagegen die Entscheidung getroffen, wenn möglich, immer ganze Texte aufzunehmen. Bei der Abfrage können dann beliebig lange Textausschnitte ausgewählt werden.
Für viele Fragestellungen ist es entscheidend, dass man die Sprachdaten annotiert, also mit Metadaten versieht.
In der Korpuslinguistik werden meist drei Typen von Annotationen unterschieden: Header-Annotationen, positionelle Annotationen und strukturelle Annotationen[15] – in unserem Korpusmodell sind alle Annotationen zur Struktur auch positionell.[16]
Header-Annotationen sind Auszeichnungen zu einem ganzen Text im Korpus. Dazu gehören etwa grundsätzliche Angaben über Textgeschichte, über Urheberschaft und Textsorte, über die Schreiberhände oder das Vorkommen von Sonderzeichen genauso wie Angaben über Vorverarbeitungsstandards und -werkzeuge. Viele dieser Angaben werden sinnvollerweise strukturiert, der Rest als Klartext beigefügt. Es gibt hier bereits sehr detaillierte Standards von der Text Encoding Initiative, auch umgesetzt im Corpus Encoding Standard[17] von EAGLES, an die sich das DDD-Projekt halten wird. Die erlaubten Annotationswerte werden im Projekt unter Rückgriff auf etablierte oder sich entwickelnde Standards, zum Beispiel ISO/TC 37/SC 4[18] standardisiert.
Detaillierte Header-Informationen ermöglichen die Zusammenstellung von Subkorpora (zum Beispiel alle Texte aus dem 16. Jahrhundert oder alle Briefe, die von Frauen geschrieben wurden). Dies ist für viele vergleichende Untersuchungen notwendig.
Positionelle Annotationen sind Angaben zu einer bestimmten Korpusposition. Im Gegensatz zu den meisten bisher üblichen Korpora ist bei uns die Bezugsgröße nicht ein Token (also in etwa ein graphisches Wort), sondern ein Zeichen. Für jeden Typ von Angaben wird eine Annotationsebene definiert. Für jede Annotationsebene gibt es ein Tagset, das die möglichen Werte spezifiziert, und Annotationsrichtlinien. Im Prinzip kann es in unserem Korpusmodell beliebig viele Annotationsebenen geben. Beispiele sind eine paläographische Ebene mit Angaben, die sich auf die Schriftzeichen beziehen, wie etwa Initialbuchstabe, Schriftfarbe und so weiter; eine Ebene zur physischen Struktur, die Zeilen, Seiten et cetera markiert; eine Ebene zur logischen Struktur, die Sätze, Absätze und dergleichen angibt, und eine Ebene zur Lemma-Annotation von Wortformen und so fort.
Eine Sonderform der positionellen Auszeichnung ist die sogenannte Alignierung, bei der die Annotation nicht aus der Zuweisung einer metatextlichen Angabe besteht, sondern aus der In-Bezug-Setzung einer oder mehrerer Textspannen der einen Textebene mit einer oder mehreren entsprechenden Textspannen derselben oder einer anderen Textebene. Beispiele sind die Alignierung von lateinischem Original und althochdeutscher Entsprechung in Interlinear-Übersetzungen oder die Alignierung von Digital-Texten mit Digitalfaksimile-Abschnitten.
Wie erwähnt, können in DDD im Prinzip beliebig viele Annotationsebenen eingeführt werden. Die Architektur kann Texte mit unterschiedlichen Auszeichnungsebenen verarbeiten. Um vergleichende Untersuchungen zu ermöglichen, haben wir uns jedoch auf einige Standards geeinigt: Die meisten Texte (das sogenannte Kernkorpus) werden mit Lemmanamen, Wortart und Flexionsmorphologie annotiert. Dabei werden wir uns für die Wortarten und Flexionsmorphologie möglichst an das Stuttgart-Tübingen-Tagset STTS[19] anlehnen. Die Lemma-Annotationen sind problematischer: Jede Sprachstufe wird eine eigene Normalisierung und Abbildung auf Lemmanamen vornehmen. Zusätzlich ist ein Hyperlemma-System vorgesehen, das die Lemmanamen der verschiedenen Sprachstufen miteinander in Beziehung setzt. Dies ist schwierig, da etymologische und semantische Beziehungen zwischen den Lemmata einander entgegenstehen können.[20]
Im Gegensatz zur automatischen Annotation für Korpora moderner Sprachen werden wir im DDD-Projekt manuell oder semi-automatisch annotieren. Dies liegt zum einen an fehlenden Ressourcen wie elektronischen Lexika und an der großen Unterschiedlichkeit der Texte (dies erschwert sowohl regelbasierte als auch statistische Verfahren) und zum anderen an den hohen Qualitätsansprüchen an ein historisches Korpus: Fehlerraten von zum Beispiel 5% oder mehr sind nicht akzeptabel.
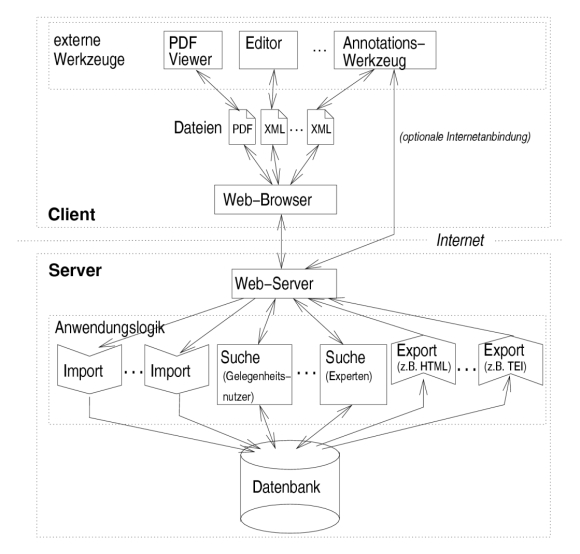
In diesem Absatz wird die technische Architektur kurz angerissen. Abbildung 1 zeigt die geplante Systemarchitektur. Wir sehen eine web-basierte Client-Server-Architektur vor, um die technischen Zugangsvoraussetzungen für die Benutzer und Benutzerinnen möglichst niedrig zu halten. Für die Abfrage des DDD-Korpus wird zunächst nur ein Web-Browser und eventuell ein PDF-Viewer benötigt. Bearbeiter von Texten des Korpus benötigen prinzipiell nur einen allgemeinen XML-Editor. Es soll jedoch ein für das verwendete XML-Format speziell angepasster Editor im Rahmen des Projekts bereitgestellt werden, welcher eine komfortablere und besser geführte Eingabe dieses Formats erlaubt. Ebenso sollen für die grammatikalische Annotation übliche Annotationswerkzeuge genutzt und – falls erforderlich – geeignet angepasst werden. Die offline bearbeiteten Texte werden mittels Web-Browser zum Server hochgeladen und durch geeignete Import-Module in die Korpus-Datenbank eingepflegt, die auf einem zentralen Server in einem relationalen Datenbanksystem vorgehalten wird.[21]
Auf diese Datenbank kann über einen Web-Server zugegriffen werden, wobei die Such-, Import- und Export-Funktionalität durch zwischengelagerte Module in der Anwendungslogik-Schicht implementiert wird.
Wir sehen unterschiedlich komplexe Suchoberflächen für unterschiedliche Nutzergruppen – von Gelegenheitsnutzern bis hin zu Expertennutzern – vor. Die Anforderungen an diese Suchfunktionalität werden weiter unten noch genauer besprochen.[22] Die Export-Module stellen die Texte des Korpus beziehungsweise Ausschnitte davon inklusive wählbarer Annotationsschichten in unterschiedlichen Dokumentformaten bereit. Als primäre Formate sehen wir XHTML für die Bildschirmrepräsentation, PDF für Druck und Offline-Präsentation sowie ein TEI-konformes[23] XML-Format für die Offline-Analyse und Bearbeitung vor. Zusätzliche Import- und Export-Formate können durch Hinzufügen entsprechender Module unterstützt werden.
Abbildung 1: Systemarchitektur
Im Gegensatz zu Digital-Ausgaben, bei denen die Suche nach einzelnen Textstellen über eine Volltextsuche im Vordergrund steht, erfordern die umfangreichen Annotationen eines linguistischen Korpus wie des DDD-Korpus ungleich komplexere Suchmöglichkeiten. Im Allgemeinen sucht man mit einer Anfrage nach Textabschnitten und Annotationen, die in einer bestimmten Beziehung zueinander stehen; sollen zum Beispiel alle Sätze gefunden werden, in denen das Wort mit dem Lemmanamen ›sagen‹ in der 1. Person Plural auftritt, so setzt das Suchergebnis für jeden Treffer jeweils eine Satz-Annotation s, eine Wort-Annotation w, eine Lemma-Annotation l und eine flexionsmorphologische Annotation f miteinander in Beziehung, wobei folgende Bedingungen erfüllt sein müssen:
Die Textspanne von s enthält die Textspanne von w, beziehungsweise w ist eine Unterannotation von s.
Die Lemma-Annotation l bezieht sich auf die Wort-Annotation w und hat den Wert ›sagen‹.
Die flexions-morphologische Annotation f bezieht sich auf die Wort-Annotation w. Das Attribut f.person hat den Wert ›1‹, und das Attribut f.numerus hat den Wert ›Plural‹.
Damit ergeben sich folgende Anforderungen an eine angemessene Suchfunktionalität für DDD:
Eine Vorauswahl von Texten zu einem Teilkorpus muss über Bedingungen auf den Header-Angaben möglich sein.
Für vergleichende Untersuchungen ist oft ein ausgewogenes Korpus notwendig. Dazu sollen Texte für die Suche auf eine bestimmte einheitliche Länge eingeschränkt werden können.
Einzelne Zeichenketten und Reguläre Ausdrücke müssen auf allen Textebenen suchbar sein.
Annotationen müssen nach Typ und anhand auf ihre Attributwerte bezogener Bedingungen auswählbar sein.
Textspannen und Annotationen müssen miteinander in Beziehung gesetzt werden können:
Einander enthaltende, direkt aufeinander folgende oder sich überschneidende Textspannen;
Textspannen in einer Textebene mit korrespondierenden Textspannen in einer alignierten Textebene;
eine Annotation mit der durch sie annotierten Textspanne;
eine Annotation mit ihren hierarchischen Nachkommen (Unterannotationen) beziehungsweise Vorfahren, beispielsweise ein Paragraph eines Texts mit den darin enthaltenen Sätzen und Wörtern aber auch mit dem Kapitel, in dem er selbst enthalten ist.
Wie in Faulstich und andere[24] näher beschrieben, orientieren wir uns beim Entwurf der Anfragesprache und Suchoberflächen an existierenden Lösungen zur Korpusanfrage wie am Corpus Query Processor[25] und an TigerSearch[26].
Zusätzlich zur Suche sollen auch quantitative Auswertungen (Stichwort: ›deskriptive Statistik‹) unterstützt werden, etwa die relative Häufigkeit bestimmter Lemmata abhängig vom Texttyp oder die Erkennung statistisch auffälliger Muster wie zum Beispiel Kollokationen[27] und von Trends, so etwa im Lauf der Zeit in Mode kommende Konstruktionen.
Bei der Suche nach Textspannen und Annotationen, aber auch bei quantitativen Untersuchungen müssen die Ergebnisse geeignet präsentiert werden. Suchergebnisse müssen im Kontext der zugrundeliegenden Texte (im Sinne von Konkordanzen) ausgegeben werden, wobei der Benutzer die engere Text-Umgebung eines Treffers nicht nur sehen, sondern, von dort ausgehend, auch den gesamten Text erkunden können soll. Es sind verschiedene Darstellungsarten denkbar, die vom Benutzer wähl- und anpassbar sein müssen. Insbesondere müssen die unterschiedlichen Text-, Annotations- und Bildebenen parallel oder alternativ sichtbar gemacht werden können und miteinander geeignet verlinkt sein. Zur Anzeige quantitativer Ergebnisse müssen entsprechende Tabellen oder Graphiken generiert werden.
In diesem Abschnitt schildern wir grob die DDD-Bearbeitungsschritte, welche ein in das Korpus einzugliedernder Text nach jetziger Planung idealerweise erfahren soll; schematisch ist dies in Abbildung 2 zusammengefasst.
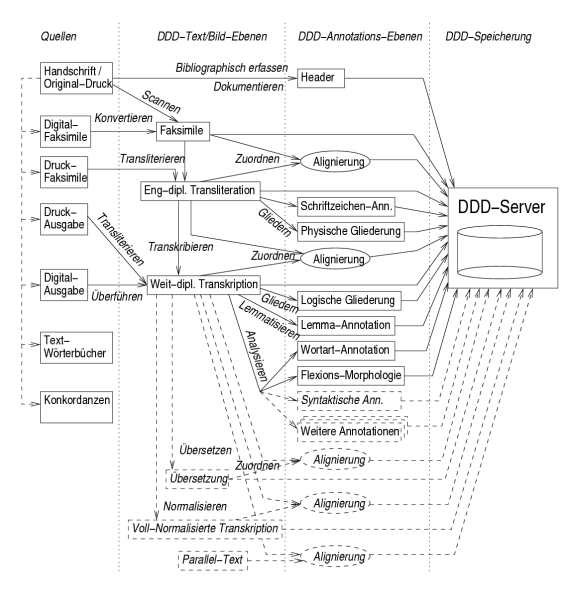
Abbildung 2: Produktionsablauf im DDD-Projekt
Grundsätzlich soll möglichst von den Primärtexten ausgegangen werden, also von Original-Handschriften oder Original-Drucken; beide liegen entweder als Urstück oder in papier- oder filmfaksimilierter Gestalt zur Bearbeitung vor. Zudem gibt es von vielen Original-Texten mehr oder minder handschriftgetreue Druckausgaben, welche zu Rate gezogen werden können (und in einigen Fällen sogar als eigene zu digitalisierende ›Primärquelle‹ gewertet werden).
Als erstes wird der zu bearbeitende Text in möglichst allen greifbaren primären (Original-Handschriften oder -Drucke) und sekundären Quellen (Papier- oder Film-Faksimiles und Druck- oder Digital-Ausgaben) gesichtet und bei Eignung und Verfügbarkeit in die Arbeit einbezogen; dabei wird es nur selten vorkommen, dass man beim Digitalisieren eine Originalquelle vorliegen hat; der Regelfall wird sein, dass entweder die digitale Fassung einer Ausgabe vorliegt, die dann noch mit einem Faksimile abzugleichen und dabei in den DDD-Standard zu überführen ist, oder aber dass unter Zuhilfenahme von Druck-Ausgaben von einem Faksimile weg eine Digitalfassung neu erstellt wird. In jedem Fall werden die Digitalfassungen in Einzelfragen noch am ›Urstück‹ (dem nichtreproduzierten Original) entlanggeführt werden müssen.
Setzen wir uns zur Veranschaulichung folgendes Digital-Faksimile als Ausgangspunkt[25]:

Abbildung 3: Ausschnitt aus einer Sachsenspiegel-Handschrift
Bei der Herstellung eines DDD-Textes sollen als erstes im Header die nötigen Angaben ausgefüllt werden (weitgehend nach den Vorgaben der Text Encoding Initiative). Hier zum Beispiel:
| <DDDCorpus> | ||
| <DDDHeader> | ||
| <title> | ||
| <h.title>Sachsenspiegel</h.title> | ||
| </title> | ||
| <author> | ||
| <h.author>Eike von Repgow</h.author> | ||
| </author> | ||
| </DDDHeader> | ||
| </DDDCorpus> |
Danach soll ein möglichst gutes Digital-Faksimile – wenn bereits verfügbar – übernommen oder aber selbst eingescannt werden, das dann mit dem Text aligniert werden kann. Im Projektantrag versprechen wir eine seitenweise Alignierung, wir werden aber versuchen, genauer zu sein und möglichst textwortweise zu alignieren.

Abbildung 4: Ausschnitt aus dem Sachsenspiegel
mit
graphischen Markierungen
Dann erfolgt unter Ausnutzung verfügbarer vorhandener Arbeiten (etwa bereits elektronisch erfasster Texte, aber auch bestehender Druck-Ausgaben, Druck-Konkordanzen und Druck-Textwörterbücher) eine den DDD-Maßgaben genügende eng-diplomatische Transliteration. Die jeweils urkundengetreueste (idealerweise also die eng-diplomatische) Fassung ist die Referenzfassung für alle weiteren Schritte. DDD nimmt alle Texte, die bis hierher bearbeitet sind, in das sogenannte Erweiterungskorpus auf.
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
… |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
S |
w |
e |
r |
l |
e |
n |
r |
e |
c |
h |
t |
|
k |
ů |
n |
n |
e |
n |
|
w |
i |
l |
· |
|
|
|
o |
l |
g |
e |
Tabelle 1: Eng-diplomatische Transliteration der ersten
Zeile
der Sachsenspiegel-Handschrift
Aus der eng-diplomatischen Fassung erstellen wir abstrahierend eine weit-diplomatische Textfassung, welche im Unterschied zu ersterer nicht mehr alle allographischen Feinheiten beibehält, sondern etwa Kürzelstriche oder Schlussbuchstabenformen normalisierend auflöst beziehungsweise vereinheitlicht. Den sprachwissenschaftlichen Annotationen dürfte sinnvollerweise diese Textfassung zugrundegelegt werden, da sie einerseits nicht mit schreiberischen/druckerischen Feinheiten des Originals überfrachtet ist, andererseits aber so urkundennah ist, dass die allermeisten sprachlich wichtigen Merkmale abfragbar sind.
|
w |
e |
r |
l |
e |
n |
r |
e |
c |
h |
t |
|
k |
ů |
n |
n |
e |
n |
|
w |
i |
l |
· |
d |
e |
r |
|
v |
o |
l |
g |
e |
Tabelle 2: Mit Tabelle 1 korrespondierende weit-diplomatische Fassung
Beide Fassungen sind miteinander aligniert:
|
S |
w |
e |
r |
l |
e |
n |
r |
e |
c |
h |
t |
|
k |
ů |
n |
n |
e |
n |
|
w |
i |
l |
· |
|
|
v |
o |
l |
g |
e |
|
S |
w |
e |
r |
l |
e |
n |
r |
e |
c |
h |
t |
|
k |
ů |
n |
n |
e |
n |
|
w |
i |
l |
· |
der |
|
v |
o |
l |
g |
e |
Tabelle 3: Alignierung von eng-diplomatischer und weit-diplomatischer Fassung
Man hat also gewissermaßen zwei Sichten auf den Text (die natürlich miteinander verbunden sind). An jede Fassung können geeignete positionelle Annotationen andocken. Zweckmäßigerweise an die eng-diplomatische Fassung können Größen wie graphische Struktur, Schreiberhände, Schriftarten, Tintenfarben, Schriftverblassungen oder Pergamentschäden annotiert werden (Tabelle 4), an die weit-diplomatische die logische Struktur, Lemmanamen, flexionsmorphologische Angaben und so weiter (Tabelle 5).
|
Ann.‑Ebenen |
Einheiten des eng‑diplomatischen Textes |
||||||||||||||||||||||
|
|
S |
w |
e |
r |
l |
e |
n |
r |
e |
c |
h |
t |
|
k |
ů |
n |
n |
e |
n |
|
w |
i |
l |
|
Typographie |
i |
|
|
|
|
|
|
|
|
Lg |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Farbe |
r |
r |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
graph. Wörter |
1 |
|
2 |
|
3 |
||||||||||||||||||
|
graph. Struktur |
1. Zeile → |
||||||||||||||||||||||
Tabelle 4: Mögliche Annotationsebenen der
eng-diplomatischen Fassung
(›i‹ steht für
›Initiale‹, ›Lg‹ für ›Ligatur‹,
›r‹ für ›rot‹)
|
Ann.‑Ebenen |
Einheiten des weit‑diplomatischen Textes |
||||||||||||||||||||||
|
|
S |
w |
e |
r |
l |
e |
n |
r |
e |
c |
h |
t |
|
k |
ů |
n |
n |
e |
n |
|
w |
i |
l |
|
logische Wörter |
1 |
2 |
|
3 |
|
4 |
|||||||||||||||||
|
Lemmaname |
swër |
lê(he)n‑rëht |
|
künnen |
|
wëllen |
|||||||||||||||||
|
Wortart |
Pron. 3.Pers. |
Substantiv (n.) |
|
Verb |
|
Verb |
|||||||||||||||||
|
nhd. Bedeutung |
wenn einer |
Lehnsrecht |
|
verstehen |
|
wollen |
|||||||||||||||||
|
Paradigmastelle |
Nom.Sg.persönl. |
Akk.Sg. |
|
Inf.Präs. |
|
3.Sg.Ind.Präs. |
|||||||||||||||||
|
logische Struktur |
1. Satz → |
||||||||||||||||||||||
Tabelle 5: Mögliche Annotations-Ebenen der weit-diplomatischen Fassung
Alle Textfassungen und Annotationsebenen sind zeichen- oder zeichenkettenweise miteinander aligniert. Zu jedem Text können dann jederzeit weitere Annotationsebenen (zum Beispiel syntaktische Struktur oder literaturwissenschaftliche Angaben) hinzugefügt werden.
Die Ablage aller Digital-Faksimiles, aller Digitaltextfassungen und aller Zusatzannotationen erfolgt zentral auf dem DDD-Server.
In diesem Papier haben wir die Konzeption eines diachronen Korpus des Deutschen dargestellt, das Texte vom 9. bis zum 19. Jahrhundert enthalten und für möglichst viele textbezogene Wissenschaften zugänglich und nutzbar sein soll.
Ein solches multilinguales und multimodales Korpus braucht zum einen eine Architektur, die das Hinzufügen von Texten und Annotationsebenen erlaubt, zum anderen eine weit reichende Standardisierung innerhalb der Annotationsebenen. Wir haben gezeigt, wie das DDD-Projekt (nach heutigem Planungsstand) diese Anforderungen umsetzen wird. Zum Schluss haben wir erläutert, wie ein Text für das Korpus bearbeitet werden soll.
Wir hoffen, mit DDD in naher Zukunft eine wertvolle und langfristig nutzbringende Forschungsressource für die Linguistik, die Philologie und alle an historischen Texten Interessierten erstellen zu können.
Anke Lüdeling, Thorwald Poschenrieder und Lukas Faulstich (Berlin)
Juniorprofessorin Anke Lüdeling,
Thorwald Poschenrieder, Dr. Lukas
Faulstich
Korpuslinguistik
Institut für deutsche Sprache und Linguistik
Humboldt-Universität zu Berlin
Unter den Linden 6
D–10099 Berlin
anke.luedeling@rz.hu-berlin.de
<http://www.linguistik.hu-berlin.de/korpuslinguistik>
(7. Februar 2005)